Intro Support Vector Machines.#
Universidad Central#
Maestría en analítica de datos#
Métodos estadísticos para analítica de datos.#
Docente: Luis Andrés Campos Maldonado.#
# Paquetes a usar.
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer, make_blobs
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC, SVR, LinearSVC
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.linear_model import SGDClassifier
plt.style.use("ggplot")
plt.rcParams["figure.figsize"] = (15,6)
url_base = "https://raw.githubusercontent.com/lacamposm/Metodos-Estadisticos/main/data/"
Introducción.#
Una máquina de vectores de soporte (SVM) es un modelo de machine learning muy potente y versátil, capaz de realizar clasificación lineal o no lineal, regresión e incluso detección de valores atípicos. Es uno de los modelos más populares en Machine Learning, y se debería tener entre las herramientas habituales. Las SVM son particularmente adecuado para la clasificación de complejos pero pequeños o medianos conjuntos de datos.
Método de SVM.#
Conceptualmente, las SVM son más fáciles de explicar para problemas de clasificación. Así que vamos con esta explicación.
Vamos a considerar el problema de clasificación de 2 clases como se muestra en la siguiente figura.

Tomado de wikipedía
La sepación de las clases se puede realizar vía un hiperplano (en este caso una recta), note que existen muchos hiperplanos que logran cumplir con la condición exigida.
El algoritmo de SVM busca responder la pregunta: ¿Cuál es el mejor hiperplano (óptimo) de separación?
La idea de mejor hiperplano dada por Vapnik es que el mejor de estos será aquel que logre tener el marguen más grande separando las 2 clases (piense en una carretera lo más ancha posible). Este será el mejor hiperplano para determinar la clase de nuevas observaciones.
Un poco de matemáticas del método.#
El hiperplano óptimo tiene por ecuación:
Donde \(\mathbf{w}\) es un vector normal (ortogonal) al hiperplano y \(b\) se conoce como el sesgo. Pensando en el problema de las 2 clases se cumple lo siguiente:
Si \(\mathbf{w}^{T}\mathbf{x}+b>0\) la clase predicha \(\hat{y}\) es la clase positiva (1).
Si \(\mathbf{w}^{T}\mathbf{x}+b < 0\) la clase predicha \(\hat{y}\) es la clase negativa (0).
Como deseamos obtener el margen más grande que separe las 2 clases vamos a considerar la distancia entre hiperplanos que pasen en los puntos más cercanos de las dos clases (vectores de soporte). Al estar los datos estandarizados, podemos reescribir las condiciones anteriores como:
Si \(\mathbf{w}^{T}\mathbf{x}+b\leq 1\), la clase predicha \(\hat{y}\) es la clase positiva (1).
Si \(\mathbf{w}^{T}\mathbf{x}+b \geq -1\), la clase predicha \(\hat{y}\) es la clase negativa (0).
Ahora, el valor del margen se obtiene como:
donde: \(\mathbf{x}_{-}\) y \(\mathbf{x}_{-}\) son vectores soporte.
De lo anterior, facilmente se obtiene que:
En resumen, debemos resolver el siguiente problema de optimización con restricciones:
Finalmente, este problema tiene un análogo en minimización y será el problema que se debe resolver con las SVM:
Donde:
\(t_{i}=-1\) para la clase negativa \(\left(\text{si }y_{i}=0\right)\) y \(t_{i}=1\) para la clase positiva \(\left(\text{si }y_{i}=1\right)\).
\(\mathbf{x}_{i}\) es un registro del dataset y la igualdad de las restricciones se cumple para los vectores de soporte.
Al derivar y pensar en el problema dual tenemos:
Soft Margin Classification.#
Si imponemos estrictamente que todas las instancias estén fuera de la margen y del lado correcto, esto se denomina hard margin classification (clasificación de margen duro). Hay dos problemas principales con el con hard margin classification.
Solo funciona si los datos son linealmente separables.
Es bastante sensible a los valores atípicos.
Para evitar estos problemas, es preferible utilizar un modelo más flexible. El objetivo es encontrar un buen equilibrio entre mantener la margen lo más grande posible y limitar las violaciones de margen (es decir, instancias que terminan dentro de la margen o incluso incluso en el lado incorrecto). Esto se llama soft margin classification.
En la clase SVM de Scikit-Learn, se puede controlar este equilibrio usando el hiperparámetro C, tenga en cuenta lo siguiente:
Un valor de
Cmás pequeño conduce a una margen más ancha pero conduce a más violaciones de la de margen.Con un valor de
Calto el clasificador comete menos violaciones de margen pero la margen en sí será pequeña.
Note que en el caso de la situación 1, parece probable que generalice mejor apesar que tiene “muchas” violaciones del margen.
Sugerencia:
Si un modelo de SVM presenta overfitting se puede intentar regularizar reduciendo el valor de C.
En este caso en el problema de optimización se necesita introducir una variable de holgura (variable slack ) \(\zeta_i\geq0\) para cada registro: \(\zeta_i\) mide cuánto se le permite al registro \(i\) violar la margen. Con esto tenemos dos objetivos en conflicto:
Hacer que las variables de holgura sean lo más pequeñas como sea posible para reducir las violaciones de margen.
Hacer que \(\frac{1}{2}\hspace{0.2em}\mathbf{w}^{T}\mathbf{w}\) lo más pequeño posible para aumentar el margen.
Aquí es donde entra el hiperparámetro C: nos permite
definir el trade-off entre estos dos objetivos. Con esto tenemos el siguiente problema de optimización con restricción:
Funciones Kernel#
¿Que podemos hacer cuando no existe la separación lineal?


Tomado de wikipedía
Una función kernel es una función definida como: \(K(x_1,x_2):\mathbb{R}^{m}\times\mathbb{R}^{m}\rightarrow\mathbb{R}\), con la particularidad de que puede ser expresado como un producto interno en otro espacio por medio de una función de mapeo \(ϕ(x):\mathbb{R}^{m}\rightarrow\mathbb{R}^{k}\). Es decir, se cumple la ecuación:
Funciones kernel más usadas.#
Para aumentar la dimensión de las variables y construir funciones más complejas se pueden usar:
Lineal $\(K(x_1,x_2)=x_1^{T}\cdot x_2\)$
Polinómico $\(K(x_1,x_2)=(x_1^{T}\cdot x_2+a)^d\)\( No se recomienda \)d>5$ por overffiting.
Gaussiana (RBF)
Sigmoid
Ejemplo 1.#
Se sugiere revisar la documentación en detalle de:
## Con load_breast_cancer de los datasets de sklearn.
cancer = load_breast_cancer()
df_cancer = pd.DataFrame(np.c_[cancer['data'], cancer['target']],
columns=np.append(cancer['feature_names'], ['target']))
print(f'Tamaño del dataset de cancer: {df_cancer.shape}')
df_cancer.sample(5)
Tamaño del dataset de cancer: (569, 31)
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 152 | 9.731 | 15.34 | 63.78 | 300.2 | 0.10720 | 0.15990 | 0.410800 | 0.07857 | 0.2548 | 0.09296 | ... | 19.49 | 71.04 | 380.5 | 0.12920 | 0.2772 | 0.82160 | 0.15710 | 0.3108 | 0.12590 | 1.0 |
| 39 | 13.480 | 20.82 | 88.40 | 559.2 | 0.10160 | 0.12550 | 0.106300 | 0.05439 | 0.1720 | 0.06419 | ... | 26.02 | 107.30 | 740.4 | 0.16100 | 0.4225 | 0.50300 | 0.22580 | 0.2807 | 0.10710 | 0.0 |
| 217 | 10.200 | 17.48 | 65.05 | 321.2 | 0.08054 | 0.05907 | 0.057740 | 0.01071 | 0.1964 | 0.06315 | ... | 24.47 | 75.40 | 403.7 | 0.09527 | 0.1397 | 0.19250 | 0.03571 | 0.2868 | 0.07809 | 1.0 |
| 556 | 10.160 | 19.59 | 64.73 | 311.7 | 0.10030 | 0.07504 | 0.005025 | 0.01116 | 0.1791 | 0.06331 | ... | 22.88 | 67.88 | 347.3 | 0.12650 | 0.1200 | 0.01005 | 0.02232 | 0.2262 | 0.06742 | 1.0 |
| 27 | 18.610 | 20.25 | 122.10 | 1094.0 | 0.09440 | 0.10660 | 0.149000 | 0.07731 | 0.1697 | 0.05699 | ... | 27.26 | 139.90 | 1403.0 | 0.13380 | 0.2117 | 0.34460 | 0.14900 | 0.2341 | 0.07421 | 0.0 |
5 rows × 31 columns
# La variables objetivo es si tiene cancer o no
df_cancer['target'].value_counts()
target
1.0 357
0.0 212
Name: count, dtype: int64
## Pequeño preprocessing de la data
scaler = StandardScaler()
X = df_cancer.drop(columns=['target'])
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
y = df_cancer['target'].astype('category')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
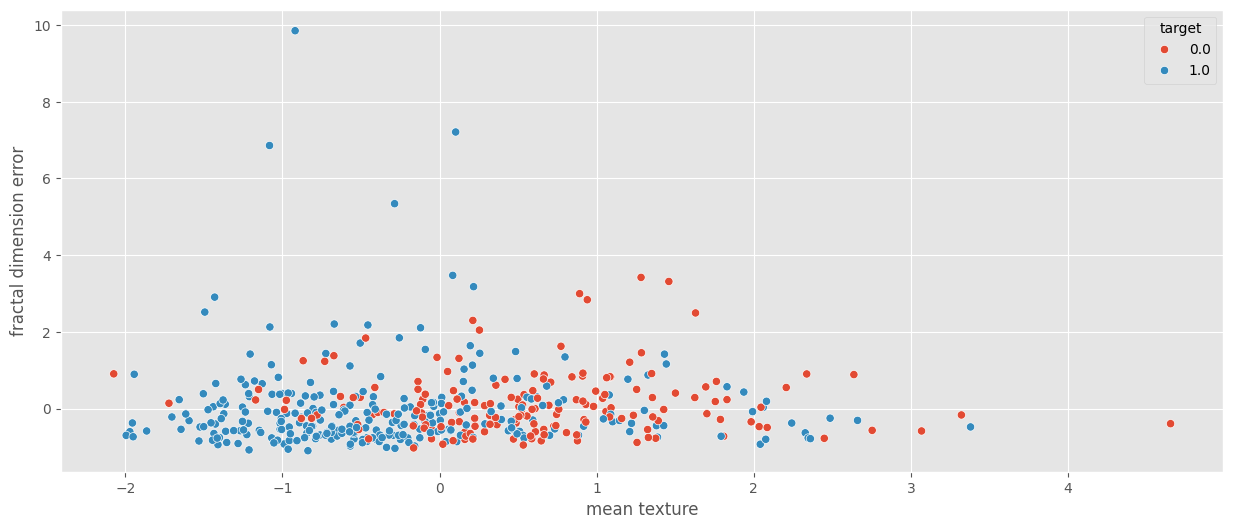
sns.scatterplot(data=X_train, x='mean texture', y='fractal dimension error', hue=y_train);
## Primer clasificador SVM
#%%time
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
SVC()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC()
%%time
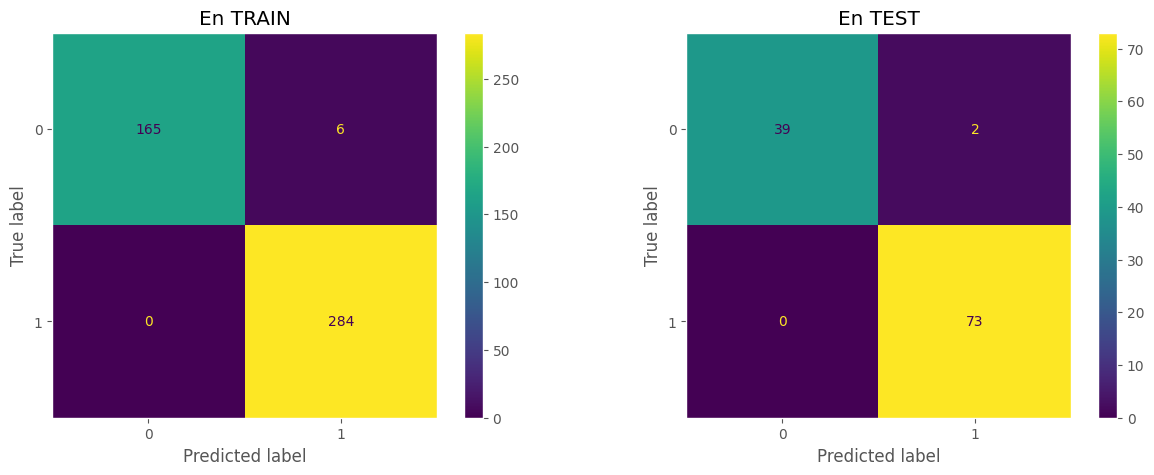
print(f'En TRAIN: {svm_clf.score(X_train,y_train)}')
print(f'En TEST: {svm_clf.score(X_test,y_test)}')
En TRAIN: 0.9868131868131869
En TEST: 0.9824561403508771
CPU times: user 6.05 ms, sys: 1.02 ms, total: 7.07 ms
Wall time: 6.26 ms
## Matriz de confusión.
prediction_train = svm_clf.predict(X_train)
cm_train = confusion_matrix(y_train,prediction_train, labels=[0,1])
disp_train = ConfusionMatrixDisplay(confusion_matrix=cm_train, display_labels=[0,1])
##
prediction_test = svm_clf.predict(X_test)
cm_test = confusion_matrix(y_test, prediction_test, labels=[0,1])
disp_test = ConfusionMatrixDisplay(confusion_matrix=cm_test, display_labels=[0,1])
## Plot confusion matrix
fig, ax = plt.subplots(1,2,figsize=(15,5))
##
disp_train.plot(ax=ax[0],)
ax[0].set_title('En TRAIN')
ax[0].grid(False)
##
disp_test.plot(ax=ax[1],)
ax[1].grid(False)
ax[1].set_title('En TEST')
##
plt.show()
## Probemos otro escalador
min_max_scaler = MinMaxScaler()
X = df_cancer.drop(columns=['target'])
X = pd.DataFrame(min_max_scaler.fit_transform(X), columns=X.columns)
y = df_cancer['target'].astype('category')
#X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
%%time
## Segundo clasificador SVM
svm_clf2 = SVC(C=1, kernel="poly")
svm_clf2.fit(X_train, y_train)
print(f"En TRAIN: {svm_clf2.score(X_train,y_train):.4f}")
print(f"En TEST: {svm_clf2.score(X_test,y_test):.4f}")
En TRAIN: 0.9121
En TEST: 0.8684
CPU times: user 7.57 ms, sys: 813 μs, total: 8.38 ms
Wall time: 8.17 ms
%%time
# Tercer clasificador SVM
svm_clf3 = SVC(C=1, kernel="linear")
svm_clf3.fit(X_train, y_train)
print(f"En TRAIN: {svm_clf3.score(X_train,y_train):.4f}")
print(f"En TEST: {svm_clf3.score(X_test,y_test):.4f}")
En TRAIN: 0.9868
En TEST: 0.9912
CPU times: user 6.92 ms, sys: 0 ns, total: 6.92 ms
Wall time: 6.72 ms
%%time
## Cuarto clasificador SVM
svm_clf4 = SVC(C=1, kernel="rbf", gamma="scale")
svm_clf4.fit(X_train, y_train)
print(f"En TRAIN: {svm_clf4.score(X_train,y_train):.4f}")
print(f"En TEST: {svm_clf4.score(X_test,y_test):.4f}")
En TRAIN: 0.9868
En TEST: 0.9825
CPU times: user 9.51 ms, sys: 0 ns, total: 9.51 ms
Wall time: 9.17 ms
## Quinto clasificador SVM
svm_clf5 = LinearSVC()
svm_clf5.fit(X_train, y_train)
print(f"En TRAIN: {svm_clf5.score(X_train,y_train):.4f}")
print(f"En TEST: {svm_clf5.score(X_test,y_test):.4f}")
En TRAIN: 0.9890
En TEST: 0.9912
## Sexto clasificador SVM
svm_clf6 = SGDClassifier()
svm_clf6.fit(X_train, y_train)
print(f"En TRAIN: {svm_clf6.score(X_train,y_train):.4f}")
print(f"En TEST: {svm_clf6.score(X_test,y_test):.4f}")
En TRAIN: 0.9824
En TEST: 0.9912
Fronteras del algoritmo.#
sns.scatterplot(data=X_train, x="mean texture", y="fractal dimension error", hue=y_train);
X_plot = X_train[['mean texture', 'fractal dimension error']].values
y_plot = y_train
minX = min(X_plot[:, 0]) - 1
maxX = max(X_plot[:, 0]) + 1
minY = min(X_plot[:, 1]) - 1
maxY = max(X_plot[:, 1]) + 1
n = 100
ax = np.linspace(minX, maxX, n)
ay = np.linspace(minY, maxY, n)
xx, yy = np.meshgrid(ax, ay)
grid_points = np.c_[xx.ravel(), yy.ravel()]
C = 1
svm_clf_plot = SVC(C=C, kernel='linear')
svm_clf_plot.fit(X_train[['mean texture', 'fractal dimension error']], y_train)
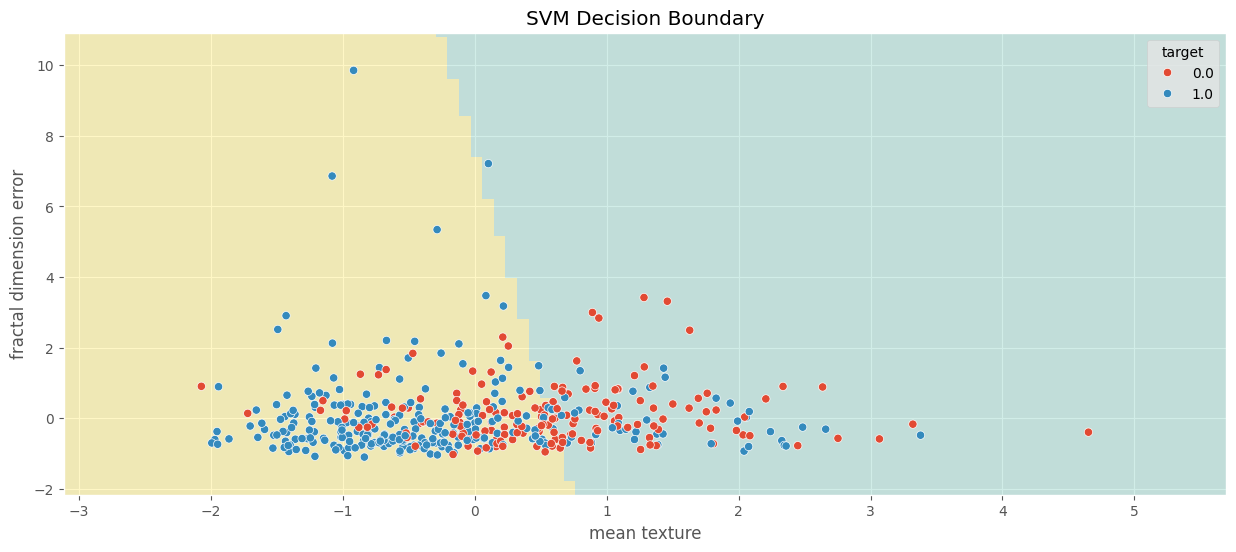
print(f'Score en TRAIN: {svm_clf_plot.score(X_plot, y_train)}')
score_test = svm_clf_plot.score(X_test[['mean texture', 'fractal dimension error']], y_test)
print(f'Score en TEST: {score_test}')
zz = svm_clf_plot.predict(grid_points)
zz = zz.reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X_plot[:, 0], y=X_plot[:, 1], hue=y_plot)
plt.xlabel('mean texture')
plt.ylabel('fractal dimension error')
plt.title('SVM Decision Boundary')
plt.show()
Score en TRAIN: 0.6967032967032967
Score en TEST: 0.6754385964912281
## Creamos el modelo SVM-rbf
C = 1
svm_clf_plot1 = SVC(C=C, kernel='rbf')
svm_clf_plot1.fit(X_train[['mean texture', 'fractal dimension error']], y_train)
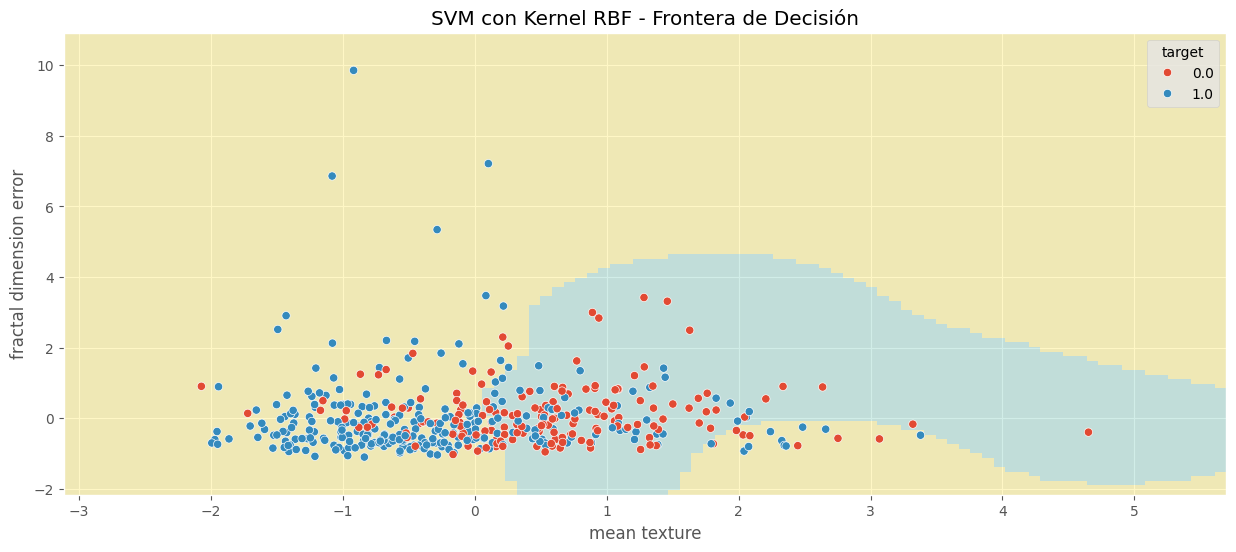
print(f'Score en TRAIN: {svm_clf_plot1.score(X_plot, y_train)}')
score_test = svm_clf_plot1.score(X_test[['mean texture', 'fractal dimension error']], y_test)
print(f'Score en TEST: {score_test}')
zz = svm_clf_plot1.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X_plot[:, 0], y=X_plot[:, 1], hue=y_plot, ax=ax)
plt.xlabel('mean texture')
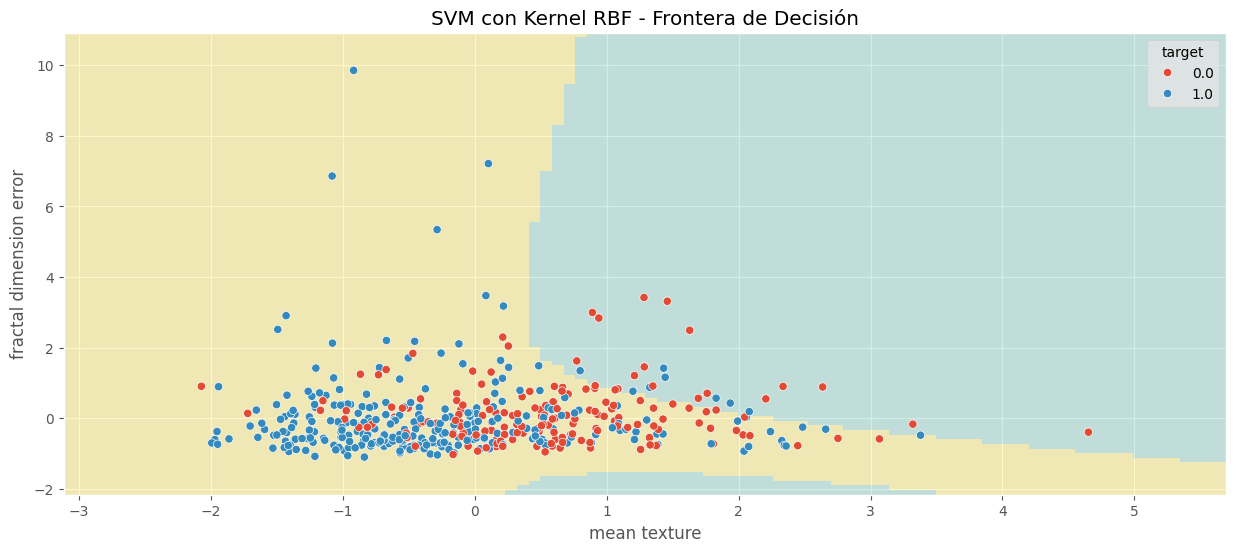
plt.ylabel('fractal dimension error')
plt.title('SVM con Kernel RBF - Frontera de Decisión')
plt.show()
Score en TRAIN: 0.7296703296703296
Score en TEST: 0.7719298245614035
## Creamos el modelo SVM-poly
C = 1
svm_clf_plot1 = SVC(C=C, kernel='poly')
svm_clf_plot1.fit(X_train[['mean texture', 'fractal dimension error']], y_train)
print(f'Score en TRAIN: {svm_clf_plot1.score(X_plot, y_train)}')
score_test = svm_clf_plot1.score(X_test[['mean texture', 'fractal dimension error']], y_test)
print(f'Score en TEST: {score_test}')
zz = svm_clf_plot1.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X_plot[:, 0], y=X_plot[:, 1], hue=y_plot, ax=ax)
plt.xlabel('mean texture')
plt.ylabel('fractal dimension error')
plt.title('SVM con Kernel RBF - Frontera de Decisión')
plt.show()
Score en TRAIN: 0.643956043956044
Score en TEST: 0.6754385964912281
## Creamos el modelo SVM-sigmoid
C = 1
svm_clf_plot1 = SVC(C=C, kernel='sigmoid')
svm_clf_plot1.fit(X_train[['mean texture', 'fractal dimension error']], y_train)
print(f'Score en TRAIN: {svm_clf_plot1.score(X_plot, y_train)}')
score_test = svm_clf_plot1.score(X_test[['mean texture', 'fractal dimension error']], y_test)
print(f'Score en TEST: {score_test}')
zz = svm_clf_plot1.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X_plot[:, 0], y=X_plot[:, 1], hue=y_plot, ax=ax)
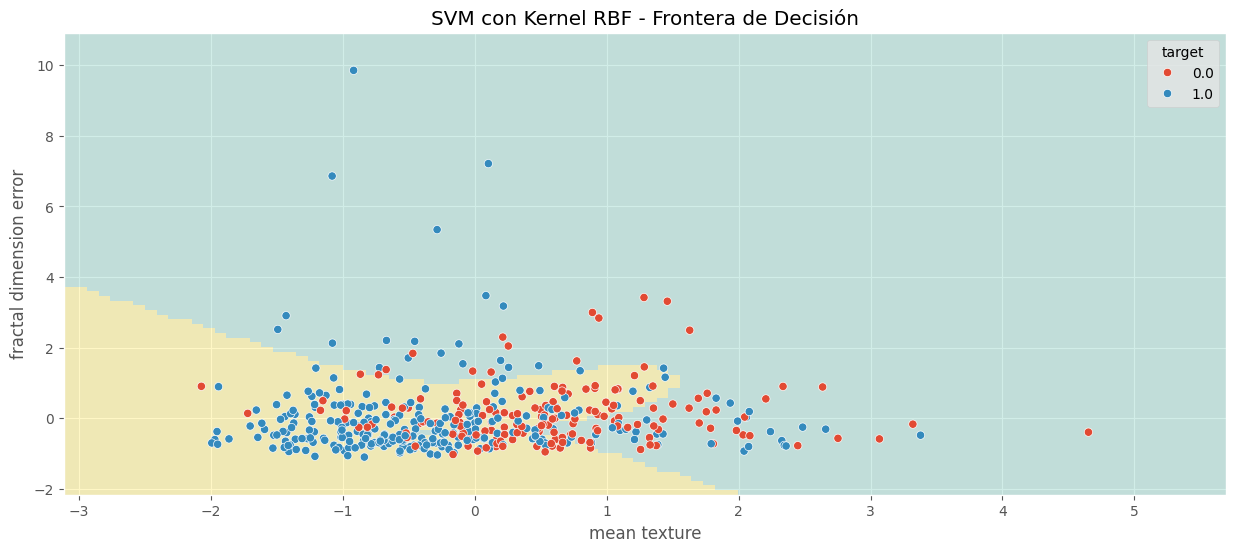
plt.xlabel('mean texture')
plt.ylabel('fractal dimension error')
plt.title('SVM con Kernel RBF - Frontera de Decisión')
plt.show()
Score en TRAIN: 0.643956043956044
Score en TEST: 0.6052631578947368
# Probemos con make_blobs
X, y = make_blobs(
n_samples=[150, 300],
random_state=123,
cluster_std=[0.5, 2.0],
center_box=(0, 2)
)
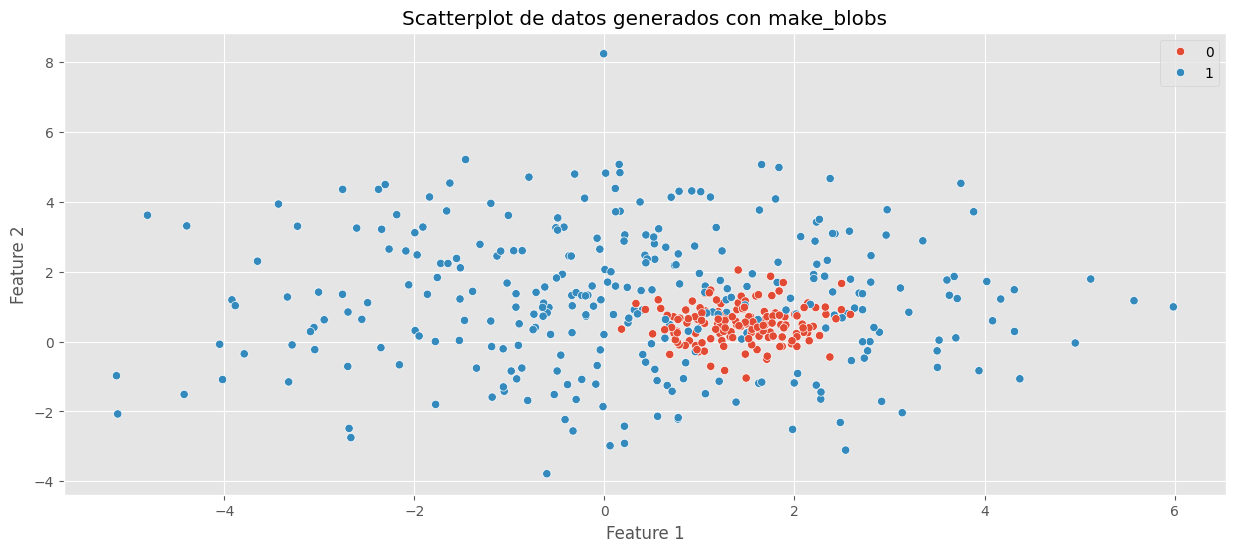
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatterplot de datos generados con make_blobs')
plt.show()
minX, maxX = X[:, 0].min() - 1, X[:, 0].max() + 1
minY, maxY = X[:, 1].min() - 1, X[:, 1].max() + 1
# Generar grid
n = 100
ax = np.linspace(minX, maxX, n)
ay = np.linspace(minY, maxY, n)
xx, yy = np.meshgrid(ax, ay)
grid_points = np.c_[xx.ravel(), yy.ravel()]
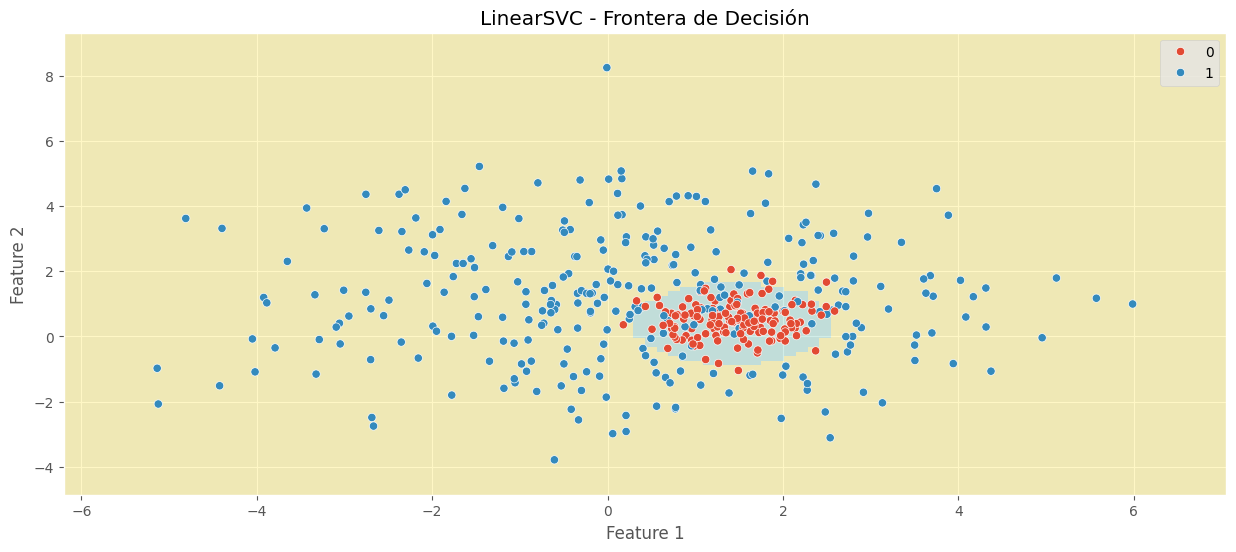
# Crear y entrenar el modelo LinearSVC
C = 1000
linear_svm = LinearSVC(C=C)
linear_svm.fit(X, y)
# Imprimir métricas
print(f"Score en TRAIN: {linear_svm.score(X, y):.4f}")
print(f"Valor hiperparámetro C de regularización: {C}")
# Predicciones para el grid
zz = linear_svm.predict(grid_points).reshape(xx.shape)
# Visualización
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap("Set3"), alpha=0.4)
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, ax=ax)
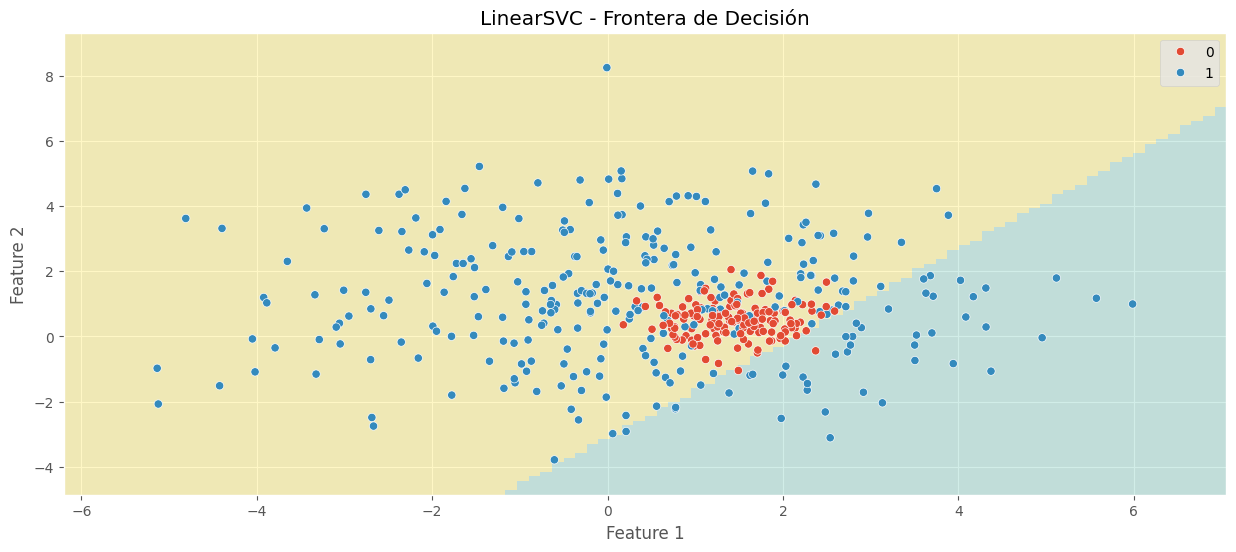
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("LinearSVC - Frontera de Decisión")
plt.show()
Score en TRAIN: 0.5778
Valor hiperparámetro C de regularización: 1000
minX = min(X[:, 0]) - 1
maxX = max(X[:, 0]) + 1
minY = min(X[:, 1]) - 1
maxY = max(X[:, 1]) + 1
n = 100
ax = np.linspace(minX, maxX, n)
ay = np.linspace(minY, maxY, n)
xx, yy = np.meshgrid(ax, ay)
grid_points = np.c_[xx.ravel(), yy.ravel()]
C = 1000
linear_svm = LinearSVC(C=C)
linear_svm.fit(X, y)
print(f'Score en TRAIN: {linear_svm.score(X, y):.4f}')
print(f'Valor hiperparámetro C de regularización: {C}')
zz = linear_svm.predict(grid_points).reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, ax=ax)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('LinearSVC - Frontera de Decisión')
plt.show()
Score en TRAIN: 0.5778
Valor hiperparámetro C de regularización: 1000
n = 100
ax = np.linspace(minX, maxX, n)
ay = np.linspace(minY, maxY, n)
xx, yy = np.meshgrid(ax, ay)
grid_points = np.c_[xx.ravel(), yy.ravel()]
C = 1
kernel = "rbf"
svm_clf_rbf = SVC(C=C, kernel=kernel)
svm_clf_rbf.fit(X, y)
print(f"Score en TRAIN: {svm_clf_rbf.score(X, y):.4f}")
print(f"Hiperparámetro C de regularización: {C}")
print(f"Kernel: {kernel}")
zz = svm_clf_rbf.predict(grid_points).reshape(xx.shape)
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap("Set3"), alpha=0.4)
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, ax=ax)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title(f"SVM con Kernel {kernel} - Frontera de Decisión")
plt.show()
Score en TRAIN: 0.9089
Hiperparámetro C de regularización: 1
Kernel: rbf
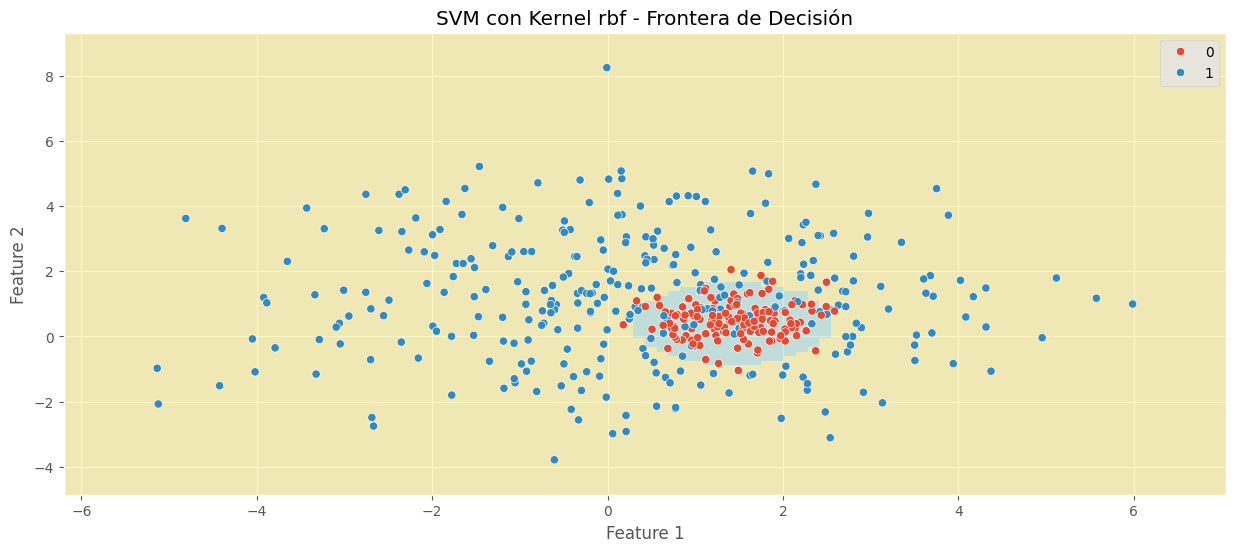
## Creamos el modelo SVM-rbf
C = 1
kernel = 'rbf'
svm_clf_rbf = SVC(C=C, kernel=kernel)
svm_clf_rbf.fit(X, y)
print(f'Score en TRAIN: {svm_clf_rbf.score(X,y):.4f}')
print(f'Hiperparámetro C de regularización: {C}')
print(f'Kernel: {kernel}')
fig, ax = plt.subplots()
plt.pcolormesh(xx, yy, zz, cmap=plt.get_cmap('Set3'), alpha=0.4)
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, ax=ax)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('LinearSVC - Frontera de Decisión')
plt.show()
Score en TRAIN: 0.9089
Hiperparámetro C de regularización: 1
Kernel: rbf
Regresión con SVM#
El algoritmo SVM es bastante versátil: no solo admite clasificación lineal y no lineal, también admite regresión lineal y no lineal. El truco consiste en invertir el objetivo, es decir, SVM en regresión trata de encajar tantos registros como sea posible en la margen mientras limita violaciones de margen (es decir, registros fuera de la margen). El ancho de la margen está controlado por el hiperparámetro ϵ.
Agregar más instancias de registros en el set de train dentro del margen no afectan las predicciones del modelo; por lo tanto, se dice que el modelo es ϵ-insensible.
Nota:
Puede utilizar la clase
LinearSVRde Scikit-Learn para realizar una regresiónSVMlineal esta implementación mejora el tiempo de entrenamiento.Para abordar tareas de regresión no lineal, puede usar un modelo
SVMkernelizado.El hiperparámetro
Csigue cumpliendo que: con valores grandes deChay poca regularización y con valores deCpequeños se obtiene mucha más regularización.La clase
SVRde scikit-learn es el método de regresión paraSVM, además puede utilizar la claseLinearSVRpara realizar una regresiónSVMlineal (kernel lineal), esta implementación mejora el tiempo de entrenamiento, pues escala linealmente con el tamaño del set de train (comoLinearSVC), mientras que la claseSVRse vuelve demasiado lenta cuando el set de train crece (al igual queSVC).
La Figura 5-10 muestra dos modelos de regresión SVM lineal entrenados en algunos datos lineales aleatorios, uno con un gran margen (ϵ=1.5) y el otro con un pequeño margen (ϵ=0,5).
El siguiente código produce el modelo representado a la izquierda de la Figura 5-10 (la formación los datos deben ser escalados y centrados primero):
en en lugar de intentar encajar el mayor posible calle entre dos clases mientras se limitan las violaciones de margen, SVM en
Ejemplo 2.#
df_boston = pd.read_csv(url_base + "boston_house_prices.csv", skiprows=1)
df_boston = df_boston.rename(columns={"MEDV": "target"})
print(f'Tamaño del dataset de boston: {df_boston.shape}')
df_boston.head()
Tamaño del dataset de boston: (506, 14)
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 5.33 | 36.2 |
# Preprocesamiento
scaler = StandardScaler()
X = df_boston.drop(columns=['target'])
y = df_boston['target']
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# Modelo SVR
svr_model = SVR(kernel="linear")
svr_model.fit(X_train, y_train)
SVR(kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(kernel='linear')
print(f'Score en TRAIN: {svr_model.score(X_train, y_train):.3f}')
print(f'Score en TEST: {svr_model.score(X_test, y_test):.3f}')
Score en TRAIN: 0.725
Score en TEST: 0.615