Análisis Factorial.#
Maestría en analítica de datos#
Métodos estadísticos para analítica de datos.#
Docente: Luis Andrés Campos Maldonado.#
# %%capture
# !pip install factor_analyzer sweetviz
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sweetviz as sv
import plotly.express as px
from utils.factor_analysis import *
from sklearn.preprocessing import StandardScaler
from factor_analyzer import FactorAnalyzer, calculate_kmo, calculate_bartlett_sphericity
warnings.filterwarnings('ignore')
plt.rcParams['figure.figsize'] = (15, 9)
plt.style.use('ggplot')
pd.set_option("display.max_columns", None)
Análisis factorial.#
El análisis factorial es una técnica multivariante utilizada para modelar las relaciones de covarianza o correlación entre un conjunto de variables observadas (medibles o manifiestas) en términos de un número menor de variables latentes no observadas, llamadas factores. Este método se emplea cuando se presume que las relaciones entre las variables observadas pueden ser explicadas por un número reducido de dimensiones subyacentes no directamente observables. Es ampliamente utilizado en psicología, sociología y otras ciencias del comportamiento, donde ciertos conceptos de interés primario a menudo no es posible medir directamente.
Dos ejemplos obvios son la inteligencia y la clase social. En tales casos, el investigador se ve obligado a examinar los conceptos indirectamente mediante la recopilación de información sobre variables que pueden medirse u observarse directamente y que también pueden asumirse de manera realista como indicadores, en algún sentido, de los conceptos de interés. El psicólogo que se interesa por la “inteligencia” de un individuo, por ejemplo, puede registrar puntajes de exámenes en una variedad de diferentes temas en la expectativa de que estos puntajes dependan de alguna manera de lo que es ampliamente considerado como “inteligencia”, pero también están sujetos a errores aleatorios. Un sociólogo, preocupado por la “clase social” de las personas podría plantear preguntas sobre la ocupación de una persona, antecedentes educativos, propiedad de vivienda, etc, en el supuesto de que estos reflejan el concepto que realmente le interesa.
Tanto la “inteligencia” como la “clase social” son lo que generalmente se conoce como variables latentes, es decir, conceptos que no se pueden medir directamente pero que se puede suponer que se relacionan con una serie de variables observadas o manifiestas. El método de análisis más generalmente utilizado para ayudar a descubrir las relaciones entre las variables latentes asumidas y las variables manifiestas es el análisis factorial. El modelo en el que se basa el método es esencialmente el de regresión múltiple, excepto que ahora las variables manifiestas son retrocedidas en las variables latente no observable (a menudo referidas en este contexto como factores comunes), de modo que la estimación de los coeficientes de regresión correspondientes (cargas factoriales) no es posible.
Variables Latentes y Manifiestas#
Los factores latentes o variables latentes son constructos teóricos no observables directamente pero que se asume afectan las variables manifiestas o variables observables. Estas últimas pueden ser medidas directamente, pero no representan de manera completa las dimensiones subyacentes que las influyen.
Tipos de Análisis Factorial#
Existen dos tipos principales de análisis factorial:
Análisis Factorial Exploratorio (AFE): Se utiliza para identificar posibles relaciones entre las variables manifiestas y los factores sin imponer restricciones a priori sobre la estructura de dichas relaciones.
Análisis Factorial Confirmatorio (AFC): Se emplea para probar hipótesis específicas sobre la relación entre las variables manifiestas y los factores, validando un modelo preespecificado.
Ejemplo del análisis factorial en la vida real.#
Imagina que una empresa realiza una encuesta a sus clientes para evaluar su satisfacción. El cuestionario incluye preguntas sobre varios aspectos del servicio, como:
Tiempo de espera en atención al cliente.
Calidad del servicio al cliente.
Claridad de la información proporcionada.
Calidad de los productos.
Facilidad para usar el sitio web.
Tiempo de entrega.
Son muchas variables y la empresa quiere entender si existen ciertos “grupos” o factores que las agrupan. Por ejemplo, podrían existir dos factores subyacentes que expliquen la mayor parte de las respuestas:
Factor 1: Experiencia de atención al cliente. Agruparía variables como el “tiempo de espera”, la “calidad del servicio” y la “claridad de la información”.
Factor 2: Calidad del producto y facilidad de uso. Incluiría variables como “calidad de los productos”, “facilidad de uso del sitio web” y “tiempo de entrega”.
Ejemplo 1.#
En el escenario para el modelo de análisis factorial, iniciamos con un solo factor. Pensemos en tres variables que son las calificaciones de exámenes en tres idiomas: clásico (\(X_1)\), Francés (\(X_2\)) e inglés (\(X_3\)), supongamos además que apartir de allí se obtiene la siguiente matriz de correlación:
Donde la matriz sigue el orden de clásico a inglés
Si asumimos un solo factor, entonces el modelo de un solo factor se especifica de la siguiente manera:
Vemos que el modelo involucra esencialmente la regresión lineal simple de cada variable observada en el único factor común. En este ejemplo, la variable latente subyacente o el factor común, \(f\), posiblemente podría equipararse con aptitud general para el aprendizaje de idiomas. Los términos \(λ_1\), \(λ_2\) y \(λ_3\) que son esencialmente, los coeficientes de regresión se conocen, en este contexto, como cargas factoriales, y los términos \(u_1\), \(u_2\) y \(u_3\) representan términos de perturbación aleatoria (ruido) y tendrá pequeñas variaciones si su variable observada asociada está estrechamente relacionada a la variable latente subyacente. La variación en \(u_i\) en realidad consta de dos partes, la medida en que la habilidad de un individuo en literatura clásica, digamos, difiere de su habilidad general y la medida en que el examen en literatura clásica es solo una medida aproximada de su habilidad en el tema. En la practica no se intenta desentrañar estas dos partes.
Tenemos en este caso que la estimación de las cargas factoriales y las varianzas específicas es muy simple, la razón es que en este caso el número de parámetros en el modelo, (tres cargas factoriales y tres varianzas específicas), es igual a el número de elementos independientes en la matriz \(R\) de correlaciones (las tres correlaciones y los tres varianzas estandarizadas diagonales), así equiparando elementos con la matriz de correlación observada a los valores correspondientes predichos por el modelo de factor único, podremos encontrar estimaciones de \(λ_1,λ_2,λ_3\), \(ψ_1,ψ_2\) y \(ψ_3\) tales que el modelo se ajusta de buena manera.
Del modelo general, de los supuestos y cuando las variables originales se han estandarizado, el analisis puede desarrollarse a partir de la matriz de correlacion, se observa que se debe resolver:
Las seis ecuaciones derivadas de la igualdad matricial implícita en el modelo de análisis factorial son:
Cuyas soluciones son:
Comentarios de los resultados#
El análisis factorial realizado sobre las calificaciones en tres idiomas (clásico, francés e inglés) reveló la existencia de un factor común subyacente que explica una parte significativa de la variabilidad en las calificaciones.
Cargas Factoriales#
Las cargas factoriales para el único factor identificado son las siguientes:
Clásico: \(\lambda_1 = 0.99\)
Francés: \(\lambda_2 = 0.84\)
Inglés: \(\lambda_3 = 0.79\)
Estas cargas indican que el factor común tiene una influencia notable en las calificaciones en todos los idiomas. En particular, la calificación en clásico está muy bien explicada por el factor común (\(\lambda_1 = 0.99\)), sugiriendo que la habilidad o competencia general en el aprendizaje de idiomas tiene una fuerte relación con el rendimiento en este idioma. Las calificaciones en francés e inglés también están significativamente influenciadas por el factor común, aunque en menor medida (\(\lambda_2 = 0.84\) y \(\lambda_3 = 0.79\), respectivamente). Esto sugiere que el factor común afecta a estas variables, pero que otras influencias pueden estar presentes.
Unicidades#
Las unicidades calculadas para cada idioma son las siguientes:
Clásico: \(\psi_1 = 0.02\)
Francés: \(\psi_2 = 0.30\)
Inglés: \(\psi_3 = 0.38\)
Las unicidades representan la proporción de la varianza de cada calificación que no está explicada por el factor común. En el caso del clásico, la unicidad es muy baja (\(\psi_1 = 0.02\)), indicando que casi toda la variabilidad en las calificaciones se explica por el factor común. Esto refuerza la fuerte asociación entre el factor común y la calificación en este idioma.
Para francés e inglés, las unicidades son mayores (\(\psi_2 = 0.30\) y \(\psi_3 = 0.38\), respectivamente), lo que sugiere que, aunque el factor común sigue siendo relevante, hay una parte considerable de la variabilidad en las calificaciones que no está explicada por este factor. Esto puede indicar la presencia de otros factores específicos que influyen en el rendimiento en estos idiomas, como la calidad del material de estudio, el interés personal o la exposición práctica al idioma.
Interpretación General#
El factor común identificado parece representar una aptitud general para el aprendizaje de idiomas. La alta carga factorial en clásico sugiere que este idioma está fuertemente relacionado con esta aptitud general. Sin embargo, para francés e inglés, aunque la aptitud general es una influencia importante, otros factores específicos del aprendizaje de cada idioma también juegan un papel significativo.
Estos resultados indican que, mientras que la aptitud general para el aprendizaje de idiomas es un factor importante que afecta a todas las calificaciones, la variabilidad específica en las calificaciones en francés e inglés sugiere que hay otros aspectos que deben ser considerados para comprender completamente el rendimiento en estos idiomas.
El \(k\)-modelo de análisis factorial#
La base del análisis factorial es un modelo de regresión que vincula las variables manifiestas con un conjunto de variables latentes no observadas (y no observables). En esencia, el modelo asume que las relaciones observadas entre las variables manifiestas (medidas por sus covarianzas o correlaciones) son el resultado de las relaciones de estas variables con las variables latentes.
Nota: Ya que son las covarianzas o correlaciones de las variables manifiestas fundamentales para el análisis factorial, se puede, en la descripción de las matemáticas del método dado, asumir que todas las variables manifiestas tienen media cero.
Supongamos que tenemos un conjunto de variables observadas o manifiestas: \(x_1, x_2, . . . , x_q\), se supone que están vinculadas a \(k\) variables latentes no observadas o factores comunes \(f_1, f_2,…, f_k\), donde \(k < q\), via la forma:
Los \(λ_{ij}\) son esencialmente los coeficientes de regresión de las variables \(x_i\) en los factores comunes, pero en el contexto del análisis factorial estos coeficientes de regresión se conocen como cargas factoriales y muestran cómo cada variable observada, \(x_i\), depende de los factores comunes. Las cargas factoriales se utilizan en la interpretación de los factores; es decir, los valores más grandes relacionan un factor con la correspondiente variables observadas y de éstas podemos a menudo, pero no siempre, inferir una descripción significativa de cada factor.
Los elementos \(f_i\) son llamados los factores comunes y los elementos \(u_i\) factores únicos o específicos.
Las ecuaciones de regresión anteriores se pueden escribir de manera más concisa como:
Suponemos que los términos de perturbación aleatoria (ruido), \(u_1,...,u_q\), no están correlacionados entre sí ni con los factores \(f_1,...,f_k\), (los elementos de \(u\) son específicos de cada \(x_i\) y, por lo tanto, generalmente se conocen mejor en este contexto como factores específicos). Los dos supuestos implican que, dados los valores de los factores comunes, las variables manifiestas son independientes; es decir, las correlaciones de las variables observadas surgen de sus relaciones con los factores comunes. Debido a que los factores no se observan, podemos fijar sus ubicaciones y escalas arbitrariamente y supondremos que ocurren en forma estandarizada con media 0 y desviación estándar 1. Supondremos también, que los factores no están correlacionados entre sí, en cuyo caso las cargas factoriales son las correlaciones de las variables manifiestas y los factores. Con estos supuestos adicionales sobre los factores, el modelo de análisis factorial implica que la varianza de la variable \(x_i\), \(σ^2_i\) , está dado por:
donde \(\psi_i\) es la varianza de \(u_i\)
De la expresión anterior la varianza de \(x_i\) puede descomponerse en dos partes, la primera:
se denomina comunalidad y representa la varianza de \(x_i\), compartida con las otras variables a travéz de los factores comunes \(f\). La segunda parte \(ψ_{i}\), representa la variabilidad exclusiva de \(x_{i}\), es decir, la varianza que no es compartida con las otras variables, esta se llama especificidad o la varianza única.
Estimación de los parámetros en el análisis k-factorial#
Para aplicar el modelo de análisis factorial descrito a una muestra de observaciones multivariadas, necesitamos estimar los parámetros del modelo de alguna manera. Estos parámetros son las cargas factoriales y las varianzas específicas, por lo que el problema de estimación en el análisis factorial es esencialmente el de encontrar \(Λ\) (la matriz de carga factorial estimada) y \(Ψ\) (la matriz diagonal que contiene las varianzas específicas estimadas), que, asumiendo el modelo factorial descrito, reproduzca con la mayor precisión posible la matriz de covarianza de la muestra, S. Esto implica:
Dada una estimación de la matriz de cargas factoriales, \(Λ\), es claramente sensato estimar las varianzas específicas como:
así, los términos de la diagonal en \(S\) se estiman exactamente.
En la práctica, el modelo factorial debe tener menos variables latentes que los datos originales, se busca entonces una descripción genuinamente parsimoniosa de los datos. Para ello se necesitan datos y métodos de estimación que traten de hacer que la matriz de covarianza predicha por el modelo factorial sea lo más cercana posible en algún sentido a la matriz de covarianza observada de las variables manifiestas. Hay tres principales métodos de estimación:
Estimación del número de factores.#
La decisión sobre cuántos factores, \(k\), se necesitan para dar una representación adecuada de las covarianzas o correlaciones observadas es generalmente crítica cuando se ajusta un modelo de análisis factorial exploratorio. Soluciones con \(k=m\) y \(k=m+1\) a menudo producirá cargas factoriales bastante diferentes para todos los factores, a diferencia de un análisis de componentes principales, en el que los primeros \(m\) componentes son idéntico en cada solución. Muchos autores señalan que: “con muy pocos factores habrá demasiadas cargas altas, y con demasiados factores, los factores pueden estar fragmentados y ser difíciles de interpretar de manera convincente.” La elección de \(k\) se puede hacer examinando soluciones correspondientes a diferentes valores de \(k\) y decidiendo subjetivamente cuál puede dar interpretación convincente. Otra posibilidad es usar el método de diagrama de sedimentación, aunque la utilidad de este método no está tan claro en el análisis factorial ya que los valores propios representan varianzas de los componenetes principales, no factores.
Acá, tomaremos el método comunmente más usado y consiste en escoger \(k\) como el número de valores propios mayores que la media de ellos. Como trabajamos factores estimados con la matriz de correlación el promedio es 1.
Rotación de factores#
El objetivo con el análisis factorial es la obtención de una estructura simple de factores o variables latentes, las cuales puedan ser identificadas por el investigador. Cuando los modelos para los factores estimados no revelen su significado, una rotación ortogonal u oblicua de éstos puede ayudar en tal sentido.
En la rotación ortogonal los factores son girados manteniendo la ortogonalidad entre éstos (rotación “rígida”), mientras que con la rotación oblicua no.
La interpretación de las ponderaciones o coeficientes factoriales es adecuada si cada variable pondera altamente en sólo un factor determinado, y si cada uno de éstos es positivo y grande o cercano a cero. Las variables se particionan en correspondencia con cada uno de los factores; las variables que se puedan asignar a más de un factor se dejan de lado. La interpretación de un factor es la característica común, media o genérica sobre las variables cuya carga es grande.
Tenemos varios tipos de rotaciones:
Varimax (ortogonal): Maximiza la varianza de las cargas factoriales al cuadrado. Tiende a producir factores con pocas cargas altas y muchas cargas cercanas a cero.
Promax (oblicua): Comienza con una rotación ortogonal y luego permite la correlación entre factores. Útil cuando se espera que los factores estén relacionados.
Oblimin (oblicua): Minimiza la covarianza de cargas factoriales. Permite gran flexibilidad en el grado de correlación entre factores.
Oblimax (ortogonal): Maximiza el número de cargas factoriales altas y bajas, minimizando las cargas intermedias. Menos común que otras rotaciones ortogonales.
Quartimin (oblicua): Caso especial de Oblimin con parámetro de simplicidad cero. Produce una solución con la máxima correlación permitida entre factores.
Quartimax (ortogonal): Maximiza la varianza de las cargas factoriales al cuadrado para cada variable. Tiende a producir un factor general y varios factores específicos.
Equamax (ortogonal): Combina criterios de Varimax y Quartimax. Busca simplificar tanto las filas como las columnas de la matriz de cargas factoriales.
¿Cuándo es adecuado hacer un análisis factorial?#
El análisis factorial tiene razón de ser cuando las variables están moderada a altamente correlacionadas; de otra manera, la búsqueda de factores comunes no tendrá resultados satisfactorios. Es importante notar que esto difiere del análisis de componentes principales, que puede ser útil incluso con correlaciones bajas. Luego, ¿son los datos apropiados para realizar el análisis factorial? La mayor parte de las medidas para este fin son de tipo heurístico o empíricas.
Una estrategia es el examen de la matriz de correlación, pues una correlación moderada a alta entre las variables indica que estas pueden ser agrupadas en conjuntos. De manera que la búsqueda se dirige hacia aquellas características o atributos englobados o agregados en cada uno de estos conjuntos: a esto se le denomina factores o variables latentes. Una correlación baja entre las variables indica que las variables no tienen mucho en común y puede no ser apropiado para el análisis factorial.
En el caso de disponer de un número grande de variables, la apreciación visual de la matriz de correlaciones puede tornarse pesada o de difícil lectura. Por lo anterior, una primera inspección es sobre el determinante de la matriz de correlaciones:
Un valor muy bajo señala alta correlación lineal entre las variables, lo cual es deseable para el análisis factorial.
No debe ser cero (matriz singular), caso en el cual se presentan algunas indeterminaciones en los cálculos, pues esto es un indicador de que algunas variables son linealmente dependientes.
Este análisis preliminar es crucial para determinar la idoneidad de los datos para el análisis factorial y para guiar las decisiones subsecuentes en el proceso analítico.
Para determinar si un conjunto de datos es apropiado para el análisis factorial, se pueden emplear varias técnicas. Dos de las más importantes son:
Prueba de esfericidad de Barlett:.
Esta prueba examina la hipótesis nula de que la matriz de correlaciones es una matriz identidad. La hipótesis se expresa como:
donde \(\text{corr}(X)\) es la matriz de correlaciones de las variables y \(I\) es la matriz identidad.
Si se rechaza \(H_0\) (p-valor < nivel de significancia, típicamente 0.05), se concluye que existe una correlación significativa entre las variables, lo cual es deseable para el análisis factorial.
Si no se rechaza \(H_0\), las variables no están lo suficientemente correlacionadas y el análisis factorial puede no ser apropiado.
El estadístico de prueba se calcula como:
donde \(n\) es el tamaño de la muestra, \(p\) es el número de variables, y \(|R|\) es el determinante de la matriz de correlaciones.
Medida de adecuación de la muestra de Kaiser-Meyer-Olkin (KMO):
El KMO es un índice que compara las magnitudes de los coeficientes de correlación observados con las magnitudes de los coeficientes de correlación parcial.
Rango: El KMO varía entre 0 y 1.
Interpretación:
KMO ≥ 0.9: Excelente
0.8 ≤ KMO < 0.9: Bueno
0.7 ≤ KMO < 0.8: Aceptable
0.6 ≤ KMO < 0.7: Regular
0.5 ≤ KMO < 0.6: Débil
KMO < 0.5: Inaceptable
La fórmula para el KMO es:
donde \(r_{ij}\) es el coeficiente de correlación simple entre las variables \(i\) y \(j\), y \(a_{ij}\) es el coeficiente de correlación parcial entre las mismas variables.
Se recomienda un valor de KMO mayor a 0.6 para considerar adecuado realizar el análisis factorial, aunque algunos autores sugieren un umbral más estricto de 0.7 o incluso 0.8.
Consideraciones Adicionales
Estas técnicas deben usarse en conjunto con otras consideraciones, como la base teórica y el propósito del estudio.
El tamaño de la muestra también es crucial. Se recomienda tener al menos 5-10 observaciones por variable, con un mínimo absoluto de 100 observaciones.
La inspección visual de la matriz de correlaciones sigue siendo una práctica valiosa, especialmente para identificar grupos de variables altamente correlacionadas.
Ejemplo 2.#
Consideremos el dataset USArrests.csv, en él se tiene 4 variables:
Murder (Asesinatos).
Assault (Asaltos).
UrbanPop (Población urbana en %).
Rape (Violación).
Los delitos están medidos en tasas por cada 100 mil habitantes, de todos los estados en EE.UU.
Para realizar el análisis factorial vamos a hacer uso del módulo factor_analyzer
# Importamos la información
url_base = "https://raw.githubusercontent.com/lacamposm/Metodos_Estadisticos/main/data/"
file_csv = "USArrests.csv"
df_ex2 = pd.read_csv(url_base + file_csv, index_col=0)
df_ex2.head()
| Murder | Assault | UrbanPop | Rape | |
|---|---|---|---|---|
| Alabama | 13.2 | 236 | 58 | 21.2 |
| Alaska | 10.0 | 263 | 48 | 44.5 |
| Arizona | 8.1 | 294 | 80 | 31.0 |
| Arkansas | 8.8 | 190 | 50 | 19.5 |
| California | 9.0 | 276 | 91 | 40.6 |
# Descriptivos básicos de la data.
df_ex2.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Murder | 50.0 | 7.788 | 4.355510 | 0.8 | 4.075 | 7.25 | 11.250 | 17.4 |
| Assault | 50.0 | 170.760 | 83.337661 | 45.0 | 109.000 | 159.00 | 249.000 | 337.0 |
| UrbanPop | 50.0 | 65.540 | 14.474763 | 32.0 | 54.500 | 66.00 | 77.750 | 91.0 |
| Rape | 50.0 | 21.232 | 9.366385 | 7.3 | 15.075 | 20.10 | 26.175 | 46.0 |
# Matriz de correlación de Pearson.
plt.figure(figsize=(12,5))
sns.heatmap(df_ex2.corr(), annot=True)
plt.title("Matriz de correlación lineal")
plt.show()
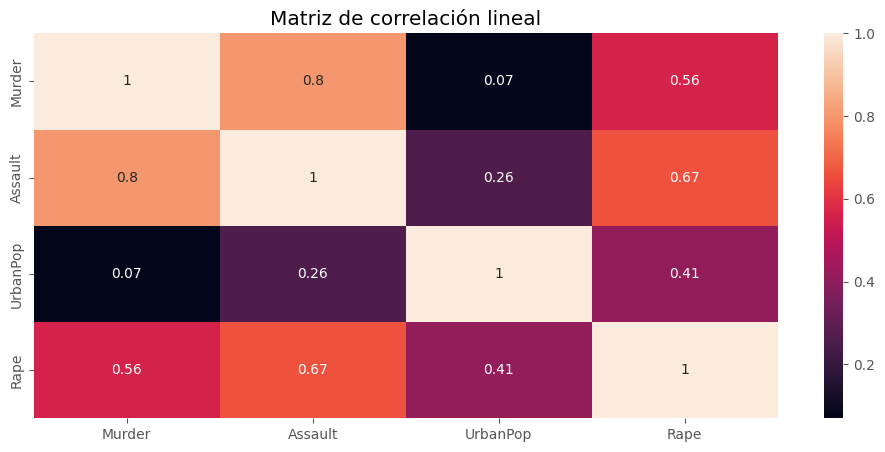
Vemos una alta correlación entre las variables, destaca el alto valor entre:
Asaltos y Asesinatos.
Asaltos y Violaciones.
Asesinatos y Violaciones.
Quizá estos 3 podrian formar una variable latente.
Paso 1.
Escalar la información.
scaler = StandardScaler() # Estandarizar el dataset.
scaler.fit(df_ex2) # Ajustar el escalador
scaled_data = scaler.transform(df_ex2) # Información escalada.
Paso 2.
Verificar que sea viable un análisis factorial.
# Calcule el criterio de Kaiser-Meyer-Olkin para el dataset. Esta estadística representa
# el grado en que cada variable observada es predicha, sin error, por las demás variables
# del conjunto de datos. En general, un KMO < 0,6 se considera inadecuado.
kmo_item, kmo_value = calculate_kmo(scaled_data)
kmo_value
0.6538150062740203
Como obtenemos un valor mayor a 0.6, procede un análisis factorial.
# Esfericidad de Barlett: Prueba la hipótesis de que la matriz de correlación es igual a la matriz
# identidad. ----> H0: La matriz de correlaciones poblacionales es igual a I.
# ----> H1: La matriz de correlaciones poblacionales no es igual a I.
# La fórmula para la prueba de esfericidad de Bartlett es:
# −1∗(n−1−((2p+5)/6))∗ln(det(R))
# Donde R det(R) es el determinante de la matriz de correlación, y p es el número de variables.
stats, p_value = calculate_bartlett_sphericity(scaled_data)
print("El p-valor para la prueba de Barlett es: {:.4f}".format(p_value))
El p-valor para la prueba de Barlett es: 0.0000
Como el \(p\)-value es pequeño rechazamos \(H_0\). Es decir, vamos por un buen camino para realizar nuestro análisis factorial.
Paso 3.
fa = FactorAnalyzer(n_factors=4, rotation=None) # Instanciamos un objeto FactorAnalyzer
fa.fit(scaled_data) # Ajustamos el análisis factorial.
FactorAnalyzer(n_factors=4, rotation=None, rotation_kwargs={})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FactorAnalyzer(n_factors=4, rotation=None, rotation_kwargs={})Paso 4.
Analizamos las salidas.
# Vemos las cargas.
loadings = view_loadings(fa, df_ex2)
loadings
| factor1 | factor2 | factor3 | factor4 | |
|---|---|---|---|---|
| Murder | 0.843704 | -0.374741 | -0.073213 | 0.0 |
| Assault | 0.919370 | -0.103672 | 0.172831 | 0.0 |
| UrbanPop | 0.331679 | 0.548848 | 0.062696 | 0.0 |
| Rape | 0.784798 | 0.292359 | -0.150257 | 0.0 |
Cada columna en la salida anterior es un factor supuesto, y cada número debajo de él corresponde a la carga.
factor1: El primer factor parece ser compuesto principalmente de asesinato, asalto y violación, con cargas de 0,84, 0,91 y 0,78, respectivamente. Esta variable latente se podría pensar como indice delictivo.
factor2 y factor3: El segundo y tercer factores no están muy bien definidos teniendo relativamente cargas pequeñas (aunque se podría argumentar a favor de un segundo factor).
Podemos obtener los valores propios de la matriz de correlación, que reflejará los obtenidos en PCA:
# Eigenvalores y eigenvectores de la matriz de correlacion.
eval, evec = fa.get_eigenvalues()
eval
array([2.48024158, 0.98976515, 0.35656318, 0.17343009])
Seguido podemos observar las comunalidades para cada variable a través de la solución factorial:
# Comunalidad: Varianza compartida con las otras variables a travéz de los factores.
pd.DataFrame(fa.get_communalities(), index=loadings.index, columns=["communality"])
| communality | |
|---|---|
| Murder | 0.857628 |
| Assault | 0.885860 |
| UrbanPop | 0.415176 |
| Rape | 0.723958 |
Podemos ver en este caso:
Para la variable
UrbanPopno hay un porcentaje alto de la variabilidad compartida con las otras variables, esto podría determinar que NO hay una buena representación de esta variable en el modelo.Hay cuatro comunalidades porque hay cuatro variables observadas (no confunda con que tenemos tres factores). Tenga en cuenta que la suma de las cargas al cuadrado en la solución factorial es igual a la comunalidad calculada.
# Comunalidad variable "Murder"
sum(loadings.loc["Murder"]**2)
0.8576275941421632
# Todas las comunalidades
loadings.apply(lambda x: sum(x**2), axis = 1)
Murder 0.857628
Assault 0.885860
UrbanPop 0.415176
Rape 0.723958
dtype: float64
# Varianza específica.
loadings.apply(lambda x: 1-sum(x**2), axis=1)
Murder 0.142372
Assault 0.114140
UrbanPop 0.584824
Rape 0.276042
dtype: float64
Rotación varimax#
Acá nuevamente obtendremos una solución de tres factores. La idea de la rotación aquí será para rotar las cargas de modo que los factores permanezcan ortogonales. Varimax intentará maximizar la varianza en las cargas para un factor dado, lo que se traduce en aumentar aún más las cargas altas y minimizar las cargas más pequeñas. Dado que los ejes originales del análisis factorial son en verdad arbitrarios, la rotación en el análisis factorial es permisible y, en un sentido fuerte, los nuevos ejes tienen tanta “verdad” para ellos como los ejes originales. ¿Qué determinará la justificación última respecto de si la rotación fue exitosa o útil? Si ayuda a tener más sentido de la solución factorial, que debe ser informada por el juicio del investigador.
# Rotación varimax. Tres factores por default.
fa_varimax = FactorAnalyzer(n_factors=3, rotation="varimax")
fa_varimax.fit(scaled_data)
FactorAnalyzer(rotation='varimax', rotation_kwargs={})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FactorAnalyzer(rotation='varimax', rotation_kwargs={})view_loadings(fa_varimax, df_ex2)
| factor1 | factor2 | factor3 | |
|---|---|---|---|
| Murder | 0.915165 | 0.027628 | 0.139060 |
| Assault | 0.880368 | 0.320204 | -0.091006 |
| UrbanPop | 0.059095 | 0.641426 | -0.016038 |
| Rape | 0.562926 | 0.595177 | 0.229863 |
Notemos que:
La rotación varimax tuvo el efecto de hacer a la variable
UrbanPopbastante irrelevante para el primer factor, disminuyendo la carga de \(0,33\) en la solución original a solo \(0,05\) en la rotación. Sin embargo, la estructura total para el primer factor permanece bastante intacta, ya que todavía se compone de asesinato, asaltos y violación.Para el segundo factor, las variables
UrbanPopyRapeson relativamente dominante en tamaño.En ambas soluciones, no se puede justificar un tercer factor, ya que en ambas soluciones, no rotadas y rotadas, las cargas son bastante pequeñas. Por lo tanto, dependiendo de la postura teórica de uno o lo que uno esperaba ver de la solución, se puede hacer un caso para una solución de un factor o de dos factores.
# Comunalidades.
pd.DataFrame(fa_varimax.get_communalities(), index=loadings.index, columns=["communality"])
| communality | |
|---|---|
| Murder | 0.857628 |
| Assault | 0.885860 |
| UrbanPop | 0.415176 |
| Rape | 0.723958 |
Vemos que UrbanPop es la variable menos relevante para
la solución factorial pues tiene una comunalidad de solo 0.41, mientras que las comunalidades de las otras variables son relativamente fuertes. Es decir, el UrbanPop no se explica tan bien por la solución factorial como las demás variables sujetas al análisis.
Ejemplo 3.#
Vamos a considerar el dataset paises.txt.
# Importamos el dataset.
data_paises = "paises.txt"
df_paises = pd.read_csv(url_base + data_paises, sep = " ", on_bad_lines='skip')
df_paises.head()
| m0 | m25 | m50 | m75 | w0 | w25 | w50 | w75 | |
|---|---|---|---|---|---|---|---|---|
| Algeria | 63 | 51 | 30 | 13 | 67 | 54 | 34 | 15 |
| Cameroon | 34 | 29 | 13 | 5 | 38 | 32 | 17 | 6 |
| Madagascar | 38 | 30 | 17 | 7 | 38 | 34 | 20 | 7 |
| Mauritius | 59 | 42 | 20 | 6 | 64 | 46 | 25 | 8 |
| Reunion | 56 | 38 | 18 | 7 | 62 | 46 | 25 | 10 |
Los datos anteriores muestran la esperanza de vida en años por país, edad y sexo (w=woman, m=men). Los datos se refieren a la esperanza de vida en los años 1960. En el DataFrame los nombres de los países son los índices y las variables en las columnas.
df_paises.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| m0 | 31.0 | 59.612903 | 7.919080 | 34.0 | 57.5 | 61.0 | 65.0 | 69.0 |
| m25 | 31.0 | 44.129032 | 5.903343 | 29.0 | 42.5 | 44.0 | 46.0 | 63.0 |
| m50 | 31.0 | 22.935484 | 3.405246 | 13.0 | 21.5 | 23.0 | 24.0 | 30.0 |
| m75 | 31.0 | 8.387097 | 2.027764 | 5.0 | 7.0 | 8.0 | 9.0 | 14.0 |
| w0 | 31.0 | 64.193548 | 8.822015 | 38.0 | 62.0 | 66.0 | 68.0 | 75.0 |
| w25 | 31.0 | 47.516129 | 4.985786 | 32.0 | 46.0 | 49.0 | 51.0 | 54.0 |
| w50 | 31.0 | 26.290323 | 3.338598 | 17.0 | 25.0 | 27.0 | 28.0 | 34.0 |
| w75 | 31.0 | 10.129032 | 2.578655 | 6.0 | 8.5 | 10.0 | 11.0 | 19.0 |
plt.figure(figsize=(12,5))
sns.heatmap(df_paises.corr(), annot=True)
plt.title("Matriz de correlación de Pearson")
plt.show()
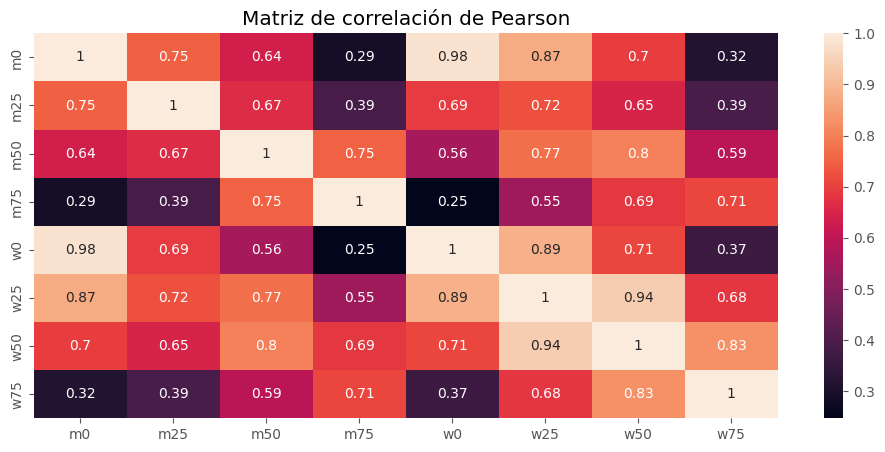
# Rutina habitual EFA.
scaler = StandardScaler()
scaler.fit(df_paises)
scaled_data = scaler.transform(df_paises)
## Calculo de KMO.
kmo_all, kmo_value = calculate_kmo(scaled_data)
print("Valor del indice KMO:", kmo_value)
# Esfericidad de Barlett.
stats, p_value = calculate_bartlett_sphericity(scaled_data)
print("El p-valor de la prueba de Barlett es: {:.3f}".format(p_value))
Valor del indice KMO: 0.794062071118025
El p-valor de la prueba de Barlett es: 0.000
Estamos en condiciones de realizar un análisis factorial.
Vamos a considerar inicialmente el análisis factorial con rotación varimax y con el método de máxima verosimilitud:
# Instanciamos un objeto FactorAnalyzer
fa_vari = FactorAnalyzer(n_factors=3, rotation="varimax", method="ml")
fa_vari.fit(scaled_data)
FactorAnalyzer(method='ml', rotation='varimax', rotation_kwargs={})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FactorAnalyzer(method='ml', rotation='varimax', rotation_kwargs={})# comunalidades
get_communa_uniquess(fa_vari, df_paises).round(4)
| comunalidades | especificidad | |
|---|---|---|
| m0 | 0.9952 | 0.0048 |
| w0 | 0.9951 | 0.0049 |
| w25 | 0.9889 | 0.0111 |
| w50 | 0.9799 | 0.0201 |
| m50 | 0.9337 | 0.0663 |
| w75 | 0.8540 | 0.1460 |
| m75 | 0.7123 | 0.2877 |
| m25 | 0.6383 | 0.3617 |
# Varianza factores, variabilidad y variabilidad acumulada.
pd.DataFrame(
fa_vari.get_factor_variance(), columns=["Factor1", "Factor2", "Factor3"],
index=["SS loadings", "Portion_Var","Cumulative_Var"]
)
| Factor1 | Factor2 | Factor3 | |
|---|---|---|---|
| SS loadings | 3.374630 | 2.082447 | 1.640295 |
| Portion_Var | 0.421829 | 0.260306 | 0.205037 |
| Cumulative_Var | 0.421829 | 0.682135 | 0.887172 |
# Vemos las cargas por columna.
for col in view_loadings(fa_vari, df_paises).columns:
print(f"Ordenado por la columna: {col}")
display(view_loadings(fa_vari, df_paises).sort_values(by=[col], ascending=False))
Ordenado por la columna: factor1
| factor1 | factor2 | factor3 | |
|---|---|---|---|
| w0 | 0.970273 | 0.217068 | 0.080928 |
| m0 | 0.963953 | 0.121610 | 0.226231 |
| w25 | 0.764143 | 0.555873 | 0.309877 |
| m25 | 0.646268 | 0.168941 | 0.438290 |
| w50 | 0.535841 | 0.729269 | 0.401149 |
| m50 | 0.429547 | 0.353621 | 0.790045 |
| w75 | 0.156155 | 0.866583 | 0.280452 |
| m75 | 0.079992 | 0.524555 | 0.656276 |
Ordenado por la columna: factor2
| factor1 | factor2 | factor3 | |
|---|---|---|---|
| w75 | 0.156155 | 0.866583 | 0.280452 |
| w50 | 0.535841 | 0.729269 | 0.401149 |
| w25 | 0.764143 | 0.555873 | 0.309877 |
| m75 | 0.079992 | 0.524555 | 0.656276 |
| m50 | 0.429547 | 0.353621 | 0.790045 |
| w0 | 0.970273 | 0.217068 | 0.080928 |
| m25 | 0.646268 | 0.168941 | 0.438290 |
| m0 | 0.963953 | 0.121610 | 0.226231 |
Ordenado por la columna: factor3
| factor1 | factor2 | factor3 | |
|---|---|---|---|
| m50 | 0.429547 | 0.353621 | 0.790045 |
| m75 | 0.079992 | 0.524555 | 0.656276 |
| m25 | 0.646268 | 0.168941 | 0.438290 |
| w50 | 0.535841 | 0.729269 | 0.401149 |
| w25 | 0.764143 | 0.555873 | 0.309877 |
| w75 | 0.156155 | 0.866583 | 0.280452 |
| m0 | 0.963953 | 0.121610 | 0.226231 |
| w0 | 0.970273 | 0.217068 | 0.080928 |
Valores cercanos a cero (m75 en el factor1, w0 en el factor3) son cargas insignificantes y no se deben tener en cuenta para ese factor.
Al examinar las cargas factoriales estimadas, vemos que el primer factor está dominado por la esperanza de vida al nacer para tanto hombres como mujeres; tal vez este factor podría denominarse: ‘fuerza vital al nacer’.
El segundo refleja las expectativas de vida a edades más avanzadas de mujeres, y podríamos etiquetarlo como: ‘fuerza vital entre las mujeres mayores’.
El tercer factor de la rotación varimax tiene sus cargas más altas para las esperanzas de vida de los hombres de 50 y 75 años y en la misma vena podría etiquetarse como: ‘fuerza vital para hombres mayores’. (Al etiquetar factores de esta manera, ¡los analistas de factores a menudo pueden ser extremadamente creativos!)
Las puntuaciones factoriales estimadas se encuentran de la siguiente manera:
# Puntuaciones factoriales
df_factor = pd.DataFrame(
fa_vari.transform(scaled_data),
columns=["factor_1", "factor_2", "factor_3"]
)
df_factor
| factor_1 | factor_2 | factor_3 | |
|---|---|---|---|
| 0 | -0.262323 | 1.932367 | 1.947489 |
| 1 | -2.828497 | -0.735350 | -1.878255 |
| 2 | -2.852813 | -0.825006 | -0.012323 |
| 3 | 0.143336 | -0.295065 | -0.872848 |
| 4 | -0.199602 | 0.482156 | -1.576108 |
| 5 | 0.373444 | 0.842704 | -0.561240 |
| 6 | -1.045575 | -0.081978 | -0.665028 |
| 7 | 0.961830 | 0.065077 | -0.935167 |
| 8 | -0.876752 | 3.651142 | -0.370443 |
| 9 | 1.265888 | 0.300545 | -0.277970 |
| 10 | 0.517150 | -0.513356 | 1.030031 |
| 11 | 0.107803 | 0.011290 | 1.869101 |
| 12 | -0.618211 | 0.661758 | 0.496471 |
| 13 | 0.239004 | -0.702676 | -0.391962 |
| 14 | 0.134192 | 0.256600 | -0.154757 |
| 15 | -1.474309 | -0.688864 | 0.670023 |
| 16 | 0.043974 | -1.882377 | 0.311387 |
| 17 | 0.469765 | -0.527764 | 0.081646 |
| 18 | -0.053198 | -0.732106 | 0.451528 |
| 19 | 0.273422 | 0.085435 | 1.733923 |
| 20 | 0.449653 | -0.749989 | 1.272872 |
| 21 | 0.723133 | -0.975749 | -0.219070 |
| 22 | 0.800302 | -1.125587 | -0.528193 |
| 23 | 1.146979 | 0.166615 | -0.693038 |
| 24 | 0.406667 | -0.368312 | -0.755225 |
| 25 | 1.234416 | 0.415544 | -0.703710 |
| 26 | 1.146979 | 0.166615 | -0.693038 |
| 27 | 0.743431 | 0.252230 | -0.130294 |
| 28 | 0.009905 | 0.764655 | -0.500080 |
| 29 | -0.244581 | -0.300326 | 0.436312 |
| 30 | -0.735407 | 0.449771 | 1.617966 |
Podemos usar las puntuaciones para proporcionar la gráfica de los datos:
px.scatter(df_factor, x="factor_1", y="factor_2", text=df_paises.index, template="plotly_white", hover_name=df_paises.index)
px.scatter(df_factor, x="factor_1", y="factor_3", text=df_paises.index, template="plotly_white")
px.scatter(df_factor, x="factor_2", y="factor_3", text=df_paises.index, template="plotly_white")
A lo largo del primer eje se refleja la ‘fuerza vital al nacer’ que va desde Camerún y Madagascar a países como Estados Unidos. En el tercer eje Argelia destaca porque tiene una alta esperanza de vida entre los hombres a edades más altas, con Camerún en el extremo inferior de la escala con una vida baja expectativa para hombres mayores de 50 años.
Ejercicio en clase:#
Vamos a considerar el dataset en el archivo stock_exer_data.txt. Este dataset muestra el semanario de las tasas de rendimiento de cinco acciones (Allied Chemical, du Pont, Union Carbide, Exxon y Texaco) que cotizan en la Bolsa de Valores de Nueva York período comprendido entre enero de 1975 y diciembre de 1976. Las tasas de rendimiento se definen como (precio de cierre del viernes actual - precio de cierre del viernes anterior precio de cierre)/(precio de cierre del viernes anterior), ajustado por división de acciones y dividendos. Las observaciones en 100 semanas sucesivas parecen estar distribuidas independientemente, pero las tasas de retorno entre las acciones están correlacionadas, ya que, como era de esperar, las acciones tienden a moverse juntas en respuesta a las condiciones económicas generales.
Para este ejercicio considere un analisis factorial con 1 y luego 2 factores. Comente.
# Importamos el dataset.
url = "https://raw.githubusercontent.com/lacamposm/Metodos_Estadisticos/main/data/stock_exer_Data.txt"
df_exer = pd.read_csv(url, sep=" ")
df_exer.head()
| Allied_Chemical | Du_Pont | Union_Carbide | Exxon | Texaco | |
|---|---|---|---|---|---|
| 0 | 0.000000 | 0.000000 | 0.000000 | 0.039473 | -0.000000 |
| 1 | 0.027027 | -0.044855 | -0.003030 | -0.014466 | 0.043478 |
| 2 | 0.122807 | 0.060773 | 0.088146 | 0.086238 | 0.078124 |
| 3 | 0.057031 | 0.029948 | 0.066808 | 0.013513 | 0.019512 |
| 4 | 0.063670 | -0.003793 | -0.039788 | -0.018644 | -0.024154 |
Ejemplo 4.#
Este ejemplo se basa en la referencia 1.
Contexto:
Este conjunto de datos contiene una encuesta de satisfacción de pasajeros de líneas aéreas. ¿Qué factores están altamente correlacionados con un pasajero satisfecho (o insatisfecho)?
Features:
Gender: Género de los pasajeros (Femenino, Masculino)
Customer Type: el tipo de cliente (cliente fiel, cliente desleal)
Age: La edad real de los pasajeros.
Type of Travel: Propósito del vuelo de los pasajeros (Personal Travel, Business Travel)
Class: Clase de viaje en el avión de los pasajeros (Business, Eco, Eco Plus)
Flight distance: Distancia de vuelo de ese viaje.
Inflight wifi service: Nivel de satisfacción del servicio wifi a bordo (0: No aplica; 1-5)
Departure/Arrival time convenient: Nivel de satisfacción de la hora de salida/llegada conveniente.
Ease of Online booking: Facilidad de reserva en línea: Nivel de satisfacción de la reserva en línea
Gate location: Nivel de satisfacción de la ubicación de la puerta
Food and drink: Nivel de satisfacción de Alimentos y bebidas
Online boarding: Nivel de satisfacción del embarque en línea
Seat comfort Nivel de satisfacción de Confort del asiento
Inflight entertainment Nivel de satisfacción del entretenimiento a bordo
On-board service: Nivel de satisfacción del servicio a bordo.
Leg room service: Nivel de satisfacción del servicio de sala de piernas
Baggage handling: Nivel de satisfacción del manejo de equipaje.
Check-in service: Nivel de satisfacción del servicio de Check-in
Inflight service: Nivel de satisfacción del servicio a bordo
Cleanliness: Nivel de satisfacción de Limpieza
Departure Delay in Minutes: Minutos de retraso en la salida.
Arrival Delay in Minutes: Minutos de retraso en la llegada.
Satisfaction: Nivel de satisfacción de la aerolínea (Satisfaction, neutral or dissatisfaction)
url_base = "https://raw.githubusercontent.com/lacamposm/Metodos_Estadisticos/main/data/"
df_kaggle1 = "train_example_FA.csv"
df_kaggle2 = "test_example_FA.csv"
df1 = pd.read_csv(url_base + df_kaggle1, index_col=0)
df2 = pd.read_csv(url_base + df_kaggle2, index_col=0)
df_original = pd.concat([df1,df2], sort=False).set_index("id")
df_original
| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 70172 | Male | Loyal Customer | 13 | Personal Travel | Eco Plus | 460 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | neutral or dissatisfied |
| 5047 | Male | disloyal Customer | 25 | Business travel | Business | 235 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | neutral or dissatisfied |
| 110028 | Female | Loyal Customer | 26 | Business travel | Business | 1142 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | satisfied |
| 24026 | Female | Loyal Customer | 25 | Business travel | Business | 562 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | neutral or dissatisfied |
| 119299 | Male | Loyal Customer | 61 | Business travel | Business | 214 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | satisfied |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 78463 | Male | disloyal Customer | 34 | Business travel | Business | 526 | 3 | 3 | 3 | 1 | 4 | 3 | 4 | 4 | 3 | 2 | 4 | 4 | 5 | 4 | 0 | 0.0 | neutral or dissatisfied |
| 71167 | Male | Loyal Customer | 23 | Business travel | Business | 646 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 4 | 0 | 0.0 | satisfied |
| 37675 | Female | Loyal Customer | 17 | Personal Travel | Eco | 828 | 2 | 5 | 1 | 5 | 2 | 1 | 2 | 2 | 4 | 3 | 4 | 5 | 4 | 2 | 0 | 0.0 | neutral or dissatisfied |
| 90086 | Male | Loyal Customer | 14 | Business travel | Business | 1127 | 3 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 3 | 2 | 5 | 4 | 5 | 4 | 0 | 0.0 | satisfied |
| 34799 | Female | Loyal Customer | 42 | Personal Travel | Eco | 264 | 2 | 5 | 2 | 5 | 4 | 2 | 2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 0 | 0.0 | neutral or dissatisfied |
129880 rows × 23 columns
my_report = sv.analyze(df_original)
my_report.show_notebook()
df = df_original.copy().iloc[:, 6:22]
df = df.dropna() # Eliminamos valores perdidos.
print("El tamaño del dataset es:", df.shape)
df.head()
El tamaño del dataset es: (129487, 16)
| Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 70172 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 |
| 5047 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 |
| 110028 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 |
| 24026 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 |
| 119299 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 |
scaler = StandardScaler() # Estandarizar el dataset.
scaler.fit(df) # Ajustar el escalador
scaled_data = scaler.transform(df) # Información escalada.
fa = FactorAnalyzer(n_factors=15, rotation="varimax")
fa.fit(scaled_data)
FactorAnalyzer(n_factors=15, rotation='varimax', rotation_kwargs={})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FactorAnalyzer(n_factors=15, rotation='varimax', rotation_kwargs={})sedimentacion(fa)
# Barlett. Sin problema.
print(calculate_bartlett_sphericity(scaled_data))
# KMO. Adecuado para análisis factorial.
calculate_kmo(scaled_data)[1]
(1100454.3463635475, 0.0)
0.7347314786302455
# Creamos el objeto y ajustamos.
fa = FactorAnalyzer(6, rotation ="varimax", method="mle")
fa.fit(scaled_data)
FactorAnalyzer(method='mle', n_factors=6, rotation='varimax',
rotation_kwargs={})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FactorAnalyzer(method='mle', n_factors=6, rotation='varimax',
rotation_kwargs={})get_communa_uniquess(fa, df)
| comunalidades | especificidad | |
|---|---|---|
| Arrival Delay in Minutes | 0.995000 | 0.005000 |
| Departure Delay in Minutes | 0.936503 | 0.063497 |
| Inflight entertainment | 0.930916 | 0.069084 |
| Ease of Online booking | 0.807665 | 0.192335 |
| Cleanliness | 0.730213 | 0.269787 |
| Online boarding | 0.675773 | 0.324227 |
| Inflight wifi service | 0.672891 | 0.327109 |
| Seat comfort | 0.666408 | 0.333592 |
| Inflight service | 0.645121 | 0.354879 |
| Food and drink | 0.586616 | 0.413384 |
| Baggage handling | 0.582458 | 0.417542 |
| On-board service | 0.505955 | 0.494045 |
| Gate location | 0.464378 | 0.535622 |
| Departure/Arrival time convenient | 0.449689 | 0.550311 |
| Checkin service | 0.302927 | 0.697073 |
| Leg room service | 0.254281 | 0.745719 |
# Varianza factores, variabilidad y variabilidad acumulada.
pd.DataFrame(
fa.get_factor_variance(), columns=[f"Factor_{i+1}" for i in range(fa.n_factors)],
index=["SS loadings", "Portion_Var","Cumulative_Var"]
)
| Factor_1 | Factor_2 | Factor_3 | Factor_4 | Factor_5 | Factor_6 | |
|---|---|---|---|---|---|---|
| SS loadings | 2.654818 | 2.255916 | 1.934291 | 1.497304 | 1.393195 | 0.471269 |
| Portion_Var | 0.165926 | 0.140995 | 0.120893 | 0.093582 | 0.087075 | 0.029454 |
| Cumulative_Var | 0.165926 | 0.306921 | 0.427814 | 0.521396 | 0.608470 | 0.637925 |
view_loadings(fa, df)
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Inflight wifi service | 0.095893 | 0.145447 | -0.010596 | 0.464849 | 0.643180 | -0.112531 |
| Departure/Arrival time convenient | -0.014038 | 0.049957 | 0.000681 | 0.652531 | 0.070951 | 0.127139 |
| Ease of Online booking | -0.032882 | 0.041106 | -0.003801 | 0.625087 | 0.636099 | -0.097589 |
| Gate location | 0.007308 | -0.025147 | 0.004322 | 0.676390 | 0.047512 | -0.062554 |
| Food and drink | 0.763137 | 0.002878 | -0.018599 | 0.027379 | 0.045003 | -0.033311 |
| Online boarding | 0.298291 | 0.073241 | -0.008257 | -0.024745 | 0.714055 | 0.266226 |
| Seat comfort | 0.767528 | 0.036403 | -0.013282 | -0.033748 | 0.154315 | 0.225512 |
| Inflight entertainment | 0.805598 | 0.498985 | -0.009547 | -0.010877 | 0.069606 | -0.166994 |
| On-board service | 0.096733 | 0.695077 | -0.020556 | -0.011837 | 0.053674 | 0.100113 |
| Leg room service | 0.063883 | 0.484207 | 0.021387 | 0.005868 | 0.123325 | 0.006515 |
| Baggage handling | 0.034816 | 0.752024 | 0.005806 | 0.044512 | -0.010826 | 0.116508 |
| Checkin service | 0.101699 | 0.238713 | -0.010906 | 0.020138 | 0.054811 | 0.481738 |
| Inflight service | 0.036162 | 0.793766 | -0.045875 | 0.044167 | -0.027277 | 0.094602 |
| Cleanliness | 0.841432 | 0.060732 | 0.000582 | 0.006888 | 0.070666 | 0.116083 |
| Departure Delay in Minutes | -0.015676 | -0.011661 | 0.967493 | 0.002168 | -0.005959 | -0.006159 |
| Arrival Delay in Minutes | -0.017171 | -0.016093 | 0.997138 | 0.001187 | -0.007650 | -0.010131 |
loadings = view_loadings(fa, df)
abs(loadings).sort_values("factor1", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Cleanliness | 0.841432 | 0.060732 | 0.000582 | 0.006888 | 0.070666 | 0.116083 |
| Inflight entertainment | 0.805598 | 0.498985 | 0.009547 | 0.010877 | 0.069606 | 0.166994 |
| Seat comfort | 0.767528 | 0.036403 | 0.013282 | 0.033748 | 0.154315 | 0.225512 |
| Food and drink | 0.763137 | 0.002878 | 0.018599 | 0.027379 | 0.045003 | 0.033311 |
| Online boarding | 0.298291 | 0.073241 | 0.008257 | 0.024745 | 0.714055 | 0.266226 |
abs(loadings).sort_values("factor2", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Inflight service | 0.036162 | 0.793766 | 0.045875 | 0.044167 | 0.027277 | 0.094602 |
| Baggage handling | 0.034816 | 0.752024 | 0.005806 | 0.044512 | 0.010826 | 0.116508 |
| On-board service | 0.096733 | 0.695077 | 0.020556 | 0.011837 | 0.053674 | 0.100113 |
| Inflight entertainment | 0.805598 | 0.498985 | 0.009547 | 0.010877 | 0.069606 | 0.166994 |
| Leg room service | 0.063883 | 0.484207 | 0.021387 | 0.005868 | 0.123325 | 0.006515 |
abs(loadings).sort_values("factor3", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Arrival Delay in Minutes | 0.017171 | 0.016093 | 0.997138 | 0.001187 | 0.007650 | 0.010131 |
| Departure Delay in Minutes | 0.015676 | 0.011661 | 0.967493 | 0.002168 | 0.005959 | 0.006159 |
| Inflight service | 0.036162 | 0.793766 | 0.045875 | 0.044167 | 0.027277 | 0.094602 |
| Leg room service | 0.063883 | 0.484207 | 0.021387 | 0.005868 | 0.123325 | 0.006515 |
| On-board service | 0.096733 | 0.695077 | 0.020556 | 0.011837 | 0.053674 | 0.100113 |
abs(loadings).sort_values("factor4", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Gate location | 0.007308 | 0.025147 | 0.004322 | 0.676390 | 0.047512 | 0.062554 |
| Departure/Arrival time convenient | 0.014038 | 0.049957 | 0.000681 | 0.652531 | 0.070951 | 0.127139 |
| Ease of Online booking | 0.032882 | 0.041106 | 0.003801 | 0.625087 | 0.636099 | 0.097589 |
| Inflight wifi service | 0.095893 | 0.145447 | 0.010596 | 0.464849 | 0.643180 | 0.112531 |
| Baggage handling | 0.034816 | 0.752024 | 0.005806 | 0.044512 | 0.010826 | 0.116508 |
abs(loadings).sort_values("factor5", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Online boarding | 0.298291 | 0.073241 | 0.008257 | 0.024745 | 0.714055 | 0.266226 |
| Inflight wifi service | 0.095893 | 0.145447 | 0.010596 | 0.464849 | 0.643180 | 0.112531 |
| Ease of Online booking | 0.032882 | 0.041106 | 0.003801 | 0.625087 | 0.636099 | 0.097589 |
| Seat comfort | 0.767528 | 0.036403 | 0.013282 | 0.033748 | 0.154315 | 0.225512 |
| Leg room service | 0.063883 | 0.484207 | 0.021387 | 0.005868 | 0.123325 | 0.006515 |
abs(loadings).sort_values("factor6", ascending=False).head()
| factor1 | factor2 | factor3 | factor4 | factor5 | factor6 | |
|---|---|---|---|---|---|---|
| Checkin service | 0.101699 | 0.238713 | 0.010906 | 0.020138 | 0.054811 | 0.481738 |
| Online boarding | 0.298291 | 0.073241 | 0.008257 | 0.024745 | 0.714055 | 0.266226 |
| Seat comfort | 0.767528 | 0.036403 | 0.013282 | 0.033748 | 0.154315 | 0.225512 |
| Inflight entertainment | 0.805598 | 0.498985 | 0.009547 | 0.010877 | 0.069606 | 0.166994 |
| Departure/Arrival time convenient | 0.014038 | 0.049957 | 0.000681 | 0.652531 | 0.070951 | 0.127139 |
Factor 1#
Cargas más altas (en valor absoluto):
Inflight entertainment: 0.8057
Cleanliness: 0.8414
Seat comfort: 0.7676
Food and drink: 0.7631
Todas las cargas son positivas, lo que indica que este factor se relaciona fuertemente con la satisfacción en cuanto a la comodidad y servicios a bordo.
Nombre propuesto: Comodidad y Entretenimiento a bordo
Factor 2#
Cargas más altas:
On-board service: 0.6951
Inflight service: 0.7938
Baggage handling: 0.7520
Leg room service: 0.4842
Las cargas también son positivas, lo que indica una relación con la calidad de servicio y manejo de equipaje durante el vuelo.
Nombre propuesto: Calidad de Servicio y Manejo de Equipaje
Factor 3#
Cargas más altas:
Arrival Delay in Minutes: 0.9970
Departure Delay in Minutes: 0.9677
Este factor se relaciona con los retrasos en la llegada y salida, y las cargas son muy altas y positivas.
Nombre propuesto: Retrasos en los vuelos
Factor 4#
Cargas más altas:
Gate location: 0.6762
Departure/Arrival time convenient: 0.6527
Ease of Online booking: 0.6252
Inflight wifi service: 0.4651
Las cargas son positivas. Este factor refleja la conveniencia de la planificación del viaje, como la ubicación de la puerta, las facilidades en la reserva y la conveniencia de los horarios.
Nombre propuesto: Conveniencia y Facilitación del Viaje
Factor 5#
Cargas más altas:
Online boarding: 0.7143 Aquí, solo una variable tiene una carga alta, que es positiva, y está relacionada con la facilidad del embarque en línea.
Nombre propuesto: Facilidad de Embarque en Línea
Factor 6#
Cargas más altas:
Checkin service: 0.4813
Similar al factor anterior, solo una variable tiene una carga alta, que es positiva, y está relacionada con el servicio de check-in.
Nombre propuesto: Calidad del Servicio de Check-in
Resumen de Nombres de Factores:#
Comodidad y Entretenimiento a bordo
Calidad de Servicio y Manejo de Equipaje
Retrasos en los vuelos
Conveniencia y Facilitación del Viaje
Facilidad de Embarque en Línea
Calidad del Servicio de Check-in
df_factor_passengers = pd.DataFrame(fa.transform(scaled_data), index=df.index, columns=[f"factor_{i+1}" for i in range(fa.n_factors)])
df_factor_passengers
| factor_1 | factor_2 | factor_3 | factor_4 | factor_5 | factor_6 | |
|---|---|---|---|---|---|---|
| id | ||||||
| 70172 | 1.216939 | 0.610483 | 0.120271 | -0.016665 | -0.109110 | 0.163606 |
| 5047 | -1.993315 | -0.408856 | -0.288581 | -0.254339 | 0.454324 | -0.694909 |
| 110028 | 1.387820 | 0.253181 | -0.356407 | -0.948140 | 0.253173 | 0.507676 |
| 24026 | -1.134814 | -0.296850 | -0.189151 | 1.599933 | -0.230451 | -0.773347 |
| 119299 | 0.158070 | -0.429373 | -0.382266 | -0.253656 | 0.820796 | 0.727466 |
| ... | ... | ... | ... | ... | ... | ... |
| 78463 | 0.406665 | 0.367459 | -0.378093 | -0.241051 | 0.065722 | 0.106701 |
| 71167 | 0.237645 | 0.943839 | -0.363949 | 0.852951 | 0.484630 | 0.670237 |
| 37675 | -1.057207 | 0.286132 | -0.412475 | 0.855135 | -1.797295 | 0.777028 |
| 90086 | 0.393108 | 0.541670 | -0.371585 | 0.098663 | 0.148876 | 0.466795 |
| 34799 | -0.781423 | -2.304916 | -0.455679 | 0.800806 | -0.884591 | -0.654502 |
129487 rows × 6 columns
display(df_factor_passengers.corr())
df_factor_passengers.describe().T
| factor_1 | factor_2 | factor_3 | factor_4 | factor_5 | factor_6 | |
|---|---|---|---|---|---|---|
| factor_1 | 1.000000 | 0.068099 | -0.000593 | -0.036222 | 0.043194 | -0.035633 |
| factor_2 | 0.068099 | 1.000000 | -0.001642 | 0.016317 | 0.002621 | -0.007281 |
| factor_3 | -0.000593 | -0.001642 | 1.000000 | 0.000689 | -0.001180 | -0.006075 |
| factor_4 | -0.036222 | 0.016317 | 0.000689 | 1.000000 | 0.196863 | -0.088211 |
| factor_5 | 0.043194 | 0.002621 | -0.001180 | 0.196863 | 1.000000 | 0.064704 |
| factor_6 | -0.035633 | -0.007281 | -0.006075 | -0.088211 | 0.064704 | 1.000000 |
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| factor_1 | 129487.0 | 6.389491e-16 | 0.953741 | -2.628578 | -0.544334 | 0.174959 | 0.639407 | 2.137827 |
| factor_2 | 129487.0 | -3.753359e-16 | 0.920797 | -3.300126 | -0.555277 | 0.135833 | 0.598642 | 2.322005 |
| factor_3 | 129487.0 | -1.896654e-15 | 0.997627 | -0.465405 | -0.392127 | -0.360137 | -0.057258 | 40.854956 |
| factor_4 | 129487.0 | 3.041373e-16 | 0.850935 | -2.738167 | -0.553005 | 0.024361 | 0.583291 | 2.426423 |
| factor_5 | 129487.0 | -1.556821e-15 | 0.867061 | -3.253490 | -0.499964 | 0.099989 | 0.602881 | 2.678632 |
| factor_6 | 129487.0 | -1.295019e-16 | 0.746539 | -3.782849 | -0.503855 | 0.037550 | 0.504650 | 3.909727 |
report_factor_analyze = sv.analyze(df_factor_passengers)
report_factor_analyze.show_notebook()
Comentatios.
Baja correlación entre factores: Los factores están bien diferenciados y capturan aspectos únicos de la experiencia del cliente, lo que valida la estructura factorial.
Factor 3 (Retrasos en los vuelos): Este factor tiene una alta variabilidad (máximo de 40.86), lo que indica que los retrasos impactan de manera diversa a los clientes y puede ser un área crítica a mejorar.
Correlación moderada entre Factor 4 (Conveniencia y Facilitación del Viaje) y Factor 5 (Facilidad de Embarque en Línea): La correlación de 0.1967 sugiere que la conveniencia del viaje y el proceso de embarque podrían estar ligeramente relacionados, por lo que las mejoras en uno pueden tener un efecto positivo en el otro.
Factores 1 y 2 (Comodidad y Calidad de Servicio): Tienen poca correlación con otros factores, lo que indica que los aspectos de confort y servicio están claramente separados de temas como los retrasos o el proceso de embarque.
Desviaciones estándar: Los factores tienen una dispersión moderada, pero Factor 3 muestra la mayor dispersión, reforzando que los retrasos generan experiencias más polarizadas entre los clientes.
import plotly.express as px
df_plot = df_original[["satisfaction"]].merge(df_factor_passengers, left_index=True, right_index=True)
for i in range(1, 7):
factor_name = f"factor_{i}"
fig = px.box(df_plot, x=factor_name, y="satisfaction", color="satisfaction", title=f"Box Plot of Satisfaction vs {factor_name}")
fig.show()