Análisis de correspondencias multiples.#
Universidad Central#
Maestría en analítica de datos#
Métodos estadísticos para analítica de datos.#
Docente: Luis Andrés Campos Maldonado.#
Protocolo de librerias#
import re
import prince
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
from utils.plots_mca import *
plt.style.use("ggplot")
plt.rcParams["figure.figsize"] = (15,6)
warnings.filterwarnings("ignore")
url_base = "https://raw.githubusercontent.com/lacamposm/Metodos_Estadisticos/main/data/"
Introducción.#
En la lectura pasada, describimos cómo calcular e interpretar el análisis de correspondencia simple, en esta lectura, mostraremos como calcular y visualizar el análisis de correspondencia múltiple en Python usando la librería prince, más algunas funciones creadas por el autor del cuaderno para la visualización de datos. Mostraremos cómo revelar las variables más importantes, es decir, aquellas que más contribuyen a explicar la
variación en el conjunto de datos.
Análisis de correspondencias múltiples.#
El análisis de correspondencia múltiple (MCA) es una extensión del análisis de correspondencia simple para resumir y visualizar una tabla de datos que contiene más de dos variables categóricas. También puede verse como una generalización del PCA cuando las variables a ser analizadas son categóricas en lugar de cuantitativas. MCA se usa generalmente para analizar un conjunto de datos de una encuesta. El objetivo es identificar:
Un grupo de individuos con perfil similar en sus respuestas a las preguntas.
Las asociaciones entre categorías de variables.
El análisis de correspondencias puede extenderse a tablas de tres o más entradas, caso en el cual se aprecia más su afinidad con el método de componentes principales. Las filas de estas tablas se consideran como los objetos o individuos y las columnas como las modalidades de las variables categóricas en estudio. Es el caso de las encuestas, donde las filas son individuos, grupos humanos o instituciones y las columnas modalidades de respuesta a las preguntas formuladas en el cuestionario o instrumento. El análisis de correspondencias múltiple (CMA) es un análisis de correspondencias simple aplicado no solo a una tabla de contingencia sino a una tabla disyuntiva completa, en el sentido de que una variable categórica asigna a cada individuo de una población una modalidad, y, en consecuencia, particiona (de manera disyuntiva y exhaustiva) a los individuos de la población.
A pesar de sus semejanzas con el análisis de correspondencias simple, el CMA tiene algunas particularidades, debido a la naturaleza misma de la tabla disyuntiva completa \((\mathbb X)\). Vamos a comentar los principios del CMA, cuando éste se desarrolla sobre la tabla disyuntiva completa.
Ejemplo 1.#
A manera de ilustración, consideremos un conjunto de \(20\) individuos a los cuales se les registra:
El grupo de edad. Modalidades: joven (1), adulto (2), anciano (3).
Sexo: Modalidades: masculino (1), femenino (2)
Nivel de estudios o escolaridad: Modalidades: primaria (1), secundaria (2), universitaria (3), otra (4)
Estrato socioeconómico. Modalidades: bajo (1), medio, (2), alto (3)
Posesión de vivienda. Modalidades: propietario (1), no propietario (2).
Se tiene entonces una matriz de datos \(R\) con 20 filas (individuos) y cinco columnas. Las entradas de esta matriz son los códigos asociados a cada modalidad de respuesta por pregunta.
R = pd.read_csv(
url_base + "Ex1_CMA.txt", sep=" ", header=None,
names=["gr_edad","sexo", "escolaridad","estrato","vivienda"]
)
R = R.astype("category")
R.head()
| gr_edad | sexo | escolaridad | estrato | vivienda | |
|---|---|---|---|---|---|
| 0 | 2 | 1 | 2 | 2 | 1 |
| 1 | 3 | 2 | 1 | 2 | 1 |
| 2 | 3 | 1 | 4 | 2 | 1 |
| 3 | 3 | 2 | 2 | 2 | 1 |
| 4 | 2 | 1 | 1 | 2 | 1 |
Así, la primera fila de la matriz \(R\) indica un hombre adulto, con estudios de secundaria, de estrato socioeconómico medio quien tiene vivienda propia. Esta matriz o tabla de datos no es tratable vía análisis de correspondencias simples; pues la suma de estos números en filas o en columnas no tienen ningún sentido. Una salida para el análisis de esta tabla es una recodificación.
Esta recodificación se logra cruzando los individuos con las combinaciones de modalidades para cada una de las preguntas; para el caso se tienen 5 preguntas con 3, 2, 4, 3 y 2 modalidades respectivamente; es decir, \(3*2*4*3*2 = 144\) posibles respuestas de los individuos.
Mediante el uso de variables indicadoras (dummies) se convierte una tabla múltiple en una tabla de doble entrada. Supóngase, en general, que a una tabla con \(k\)-variables (o preguntas) donde cada una tiene \(p_i\) modalidades o categorías (para \(i = 1, . . . , k\)), se asocia, de manera adecuada, una variable indicadora a cada una de las modalidades asociadas con cada una de las variables columna de la tabla. La codificación dada por \(p_i\), hace corresponder tantas variables binarias como modalidades tenga la variable categórica. El total de modalidades es igual a \(\sum_{i}^{k}p_i = p\).
Un individuo particular se codifica con uno (1) si el individuo posee el atributo de la respectiva modalidad y con cero (0) en las demás modalidades de la misma variable, pues se asume que las modalidades son excluyentes. Resulta entonces una matriz \(\mathbb X\) de tamaño \((n×p)\) formada por bloques columna, cada uno de los cuales hace referencia a una variable registrada sobre los \(n\) individuos.
Para la matriz \(R\) anterior la codificación se realiza teniendo en cuenta que las modalidades de cada variable se consideran como variables de tipo dicotómico; cada individuo toma sólo el valor de 1 en una única modalidad y de 0 en las demás modalidades de la misma variable.
# Variables dummies.
pd.get_dummies(R, dtype=int).head()
| gr_edad_1 | gr_edad_2 | gr_edad_3 | sexo_1 | sexo_2 | escolaridad_1 | escolaridad_2 | escolaridad_3 | escolaridad_4 | estrato_1 | estrato_2 | estrato_3 | vivienda_1 | vivienda_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
La suma en cada una de las filas es constante, en este caso \(p=5\), mientras que la suma en las columnas \(n_j\) \((j = 1, . . . , 14)\) suministra el número de individuos que participan en cada una de las 14 modalidades. La tabla o matriz \(\mathbb X\) con \(n\)-filas y \(p\)-columnas describe las \(k\)-respuestas de los \(n\)-individuos a través de un código binario (0 o 1) y se le llama tabla disyuntiva completa. Esta tabla es la unión de \(k\) tablas (una por pregunta).
Bases del análisis de correspondencias múltiples.#
El análisis de correspondencias múltiples es un análisis de correspondencia simple, aplicado a la tabla disyunta completa.
Un grupo de individuos es similar si éstos asumen aproximadamente las mismas variables. La asociación entre variables se presenta porque son casi que los mismos individuos quienes asumen las mismas modalidades de diferentes variables.
El análisis de correspondencias múltiples encuentra asociaciones entre variables de tipo categórico a través de las respectivas modalidades de éstas.
En este análisis se considera la nube de puntos fila (\(n\) puntos) y la nube de puntos columna (\(p\) puntos).
Las modalidades de frecuencia baja (las “raras”) están alejadas de las otras modalidades.
Dos individuos están próximos si ellos han seleccionado las mismas modalidades. Los individuos están alejados si no han respondido de la misma manera.
Propiedades del análisis de correspondencias múltiples.#
A diferencia del análisis de componentes principales, los primeros ejes, aún en forma creciente, explican una pequeña parte de la variabilidad total.
La distancia de una modalidad al origen en el CMA es inversamente proporcional a su participación \(n_j\). Es decir, modalidades con participación baja (\(n_j\) pequeño) aparecen más alejadas del origen que las modalidades de mayor frecuencia.
Las modalidades o categorías de una variable están centradas; es decir, el centro de las modalidades de una misma variable es el origen del “nuevo” sistema de coordenadas. Así, las modalidades de una variable dicotómica se ubicarán en forma opuesta al origen.
El CMA es una descomposición de la nube de puntos de la varianza o inercia total del espacio de individuos (filas) o del espacio de las modalidades (columnas), en ciertas direcciones ortogonales, de tal forma que en cada dirección se maximice la inercia explicada.
Así como en el PCA la influencia de cada variable está dada por su varianza, las modalidades situadas a mayor distancia tienen la mayor inercia, luego son las más influyentes y de acuerdo con la propiedad (2.), son las que tienen menor número de individuos.
Reglas para la interpretación.#
Decir que existen afinidades entre respuestas, equivale a decir que hay individuos que han seleccionado simultáneamente todas o casi todas, las mismas respuestas. El análisis de correspondencias múltiples pone en evidencia a los individuos con perfiles semejantes respecto a los atributos seleccionados para su descripción.
De acuerdo con las distancias entre elementos de la tabla disyuntiva completa y las relaciones baricéntricas (idea de que un individuo, en el análisis de correspondencias, se ubica en el espacio geométrico cerca del centro de gravedad (baricentro) de las categorías con las que está más asociado, reflejando sus relaciones con esas categorías de manera visual), se expresa:
La cercanía entre individuos en términos de semejanzas; es decir, dos individuos son semejantes si han seleccionado globalmente las mismas modalidades.
La proximidad entre modalidades de variables diferentes en términos de asociación; es decir, estas modalidades corresponden a puntos medios de los individuos que las han seleccionado, y son próximas porque están ligadas a los mismos individuos o individuos parecidos.
La proximidad entre dos modalidades de una misma variable en términos de semejanza; por construcción, las modalidades de una misma variable son excluyentes. Si ellas están cerca, su proximidad se interpreta en términos de semejanza entre los grupos de individuos que las han seleccionado.
La contribución de una variable a un factor se calcula sumando las contribuciones de las respectivas modalidades sobre ese factor. Así, se debe prestar atención a las variables que participan en la definición del factor, de acuerdo con las modalidades más “responsables” de los ejes factoriales.
Las reglas de interpretación de los resultados, tales como coordenadas, contribuciones, cosenos cuadrados, son casi las mismas que las dispuestas para el análisis de correspondencias simples.
Matriz de Burt#
R_dummies = pd.get_dummies(R.drop(columns=["estrato"]), dtype=int)
burt_table = R_dummies.T @ R_dummies
pd.DataFrame(burt_table)
| gr_edad_1 | gr_edad_2 | gr_edad_3 | sexo_1 | sexo_2 | escolaridad_1 | escolaridad_2 | escolaridad_3 | escolaridad_4 | vivienda_1 | vivienda_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| gr_edad_1 | 5 | 0 | 0 | 3 | 2 | 1 | 2 | 2 | 0 | 3 | 2 |
| gr_edad_2 | 0 | 7 | 0 | 3 | 4 | 1 | 5 | 0 | 1 | 5 | 2 |
| gr_edad_3 | 0 | 0 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 7 | 1 |
| sexo_1 | 3 | 3 | 4 | 10 | 0 | 3 | 3 | 2 | 2 | 6 | 4 |
| sexo_2 | 2 | 4 | 4 | 0 | 10 | 1 | 6 | 2 | 1 | 9 | 1 |
| escolaridad_1 | 1 | 1 | 2 | 3 | 1 | 4 | 0 | 0 | 0 | 2 | 2 |
| escolaridad_2 | 2 | 5 | 2 | 3 | 6 | 0 | 9 | 0 | 0 | 6 | 3 |
| escolaridad_3 | 2 | 0 | 2 | 2 | 2 | 0 | 0 | 4 | 0 | 4 | 0 |
| escolaridad_4 | 0 | 1 | 2 | 2 | 1 | 0 | 0 | 0 | 3 | 3 | 0 |
| vivienda_1 | 3 | 5 | 7 | 6 | 9 | 2 | 6 | 4 | 3 | 15 | 0 |
| vivienda_2 | 2 | 2 | 1 | 4 | 1 | 2 | 3 | 0 | 0 | 0 | 5 |
Retomando ejemplo 1.#
df = pd.read_csv(
url_base + "Ex1_CMA.txt", sep=" ", header=None,
names=["gr_edad", "sexo", "escolaridad", "estrato", "vivienda"]
)
df = df.astype("category")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gr_edad 20 non-null category
1 sexo 20 non-null category
2 escolaridad 20 non-null category
3 estrato 20 non-null category
4 vivienda 20 non-null category
dtypes: category(5)
memory usage: 944.0 bytes
# get_dummies()
X = pd.get_dummies(df, dtype=int)
X
| gr_edad_1 | gr_edad_2 | gr_edad_3 | sexo_1 | sexo_2 | escolaridad_1 | escolaridad_2 | escolaridad_3 | escolaridad_4 | estrato_1 | estrato_2 | estrato_3 | vivienda_1 | vivienda_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 5 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 7 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 8 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 9 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 10 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 11 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 12 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 13 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 14 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 15 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 16 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 17 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 18 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 19 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
# df_ex1 es el dataset del primer ejemplo
df_ex1 = df.copy()
df_ex1.drop(columns=["estrato"], inplace=True)
df_ex1.head()
| gr_edad | sexo | escolaridad | vivienda | |
|---|---|---|---|---|
| 0 | 2 | 1 | 2 | 1 |
| 1 | 3 | 2 | 1 | 1 |
| 2 | 3 | 1 | 4 | 1 |
| 3 | 3 | 2 | 2 | 1 |
| 4 | 2 | 1 | 1 | 1 |
# get_dummies()
X1 = pd.get_dummies(df_ex1, drop_first=True)
# Número de "dof" para cada variable categórica = # Categorias - 1.
# Número de valores propios no nulos.
len(X1.columns)
7
# Tabla de datos disyunta completa.
X1 = pd.get_dummies(df_ex1, dtype=int); X1
| gr_edad_1 | gr_edad_2 | gr_edad_3 | sexo_1 | sexo_2 | escolaridad_1 | escolaridad_2 | escolaridad_3 | escolaridad_4 | vivienda_1 | vivienda_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 5 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 7 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 8 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 9 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 10 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 11 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 12 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 13 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 14 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 15 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 16 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 17 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 18 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| 19 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
# Realizamos CA en X1 que es get_dummies del DataFrame df_ex1
ca = prince.CA(n_components=7, random_state=42).fit(X1)
ca
<prince.ca.CA at 0x77560868d4b0>
La proporción de varianzas retenidas por las diferentes dimensiones (ejes) se puede extraer usando el
atributo: eigenvalues_summary del objeto CA de Prince
ca.eigenvalues_summary
| eigenvalue | % of variance | % of variance (cumulative) | |
|---|---|---|---|
| component | |||
| 0 | 0.419 | 23.97% | 23.97% |
| 1 | 0.389 | 22.24% | 46.20% |
| 2 | 0.331 | 18.93% | 65.13% |
| 3 | 0.221 | 12.65% | 77.78% |
| 4 | 0.156 | 8.89% | 86.68% |
| 5 | 0.143 | 8.16% | 94.83% |
| 6 | 0.090 | 5.17% | 100.00% |
Comentarios:
Tenemos 7 valores propios, la inercia ligada a cada valor propio varía entre \(0.419\) para el valor propio más grande y \(0.090\) para el más pequeño.
Debemos tener cuidado de emplear los valores propios y las tasas de inercia como indicadores del número de ejes apropiados. Sin embargo, obsérvese que con los dos primeros ejes reúnen el \(46.2\%\) de la inercia total.
Para efectos de interpretación de los datos, se puede y se debe hacer el análisis sobre el primer plano factorial y sobre otros planos tales como el factor 1 vs el factor 3, por ejemplo.
La calidad de la representación (\(cos2\)), mide el grado de asociación entre las categorías de las variables y un eje particular:
# Tabla con información sobre los 2 primeros factores.
tmp = ca.column_coordinates(X1)[[0,1]].rename(columns={0: "factor_1", 1: "factor_2"})
tmp1 = get_cos2(ca, X1, choice="columns")[["Dim1","Dim2"]]
tmp.merge(tmp1, left_index=True, right_index=True)
| factor_1 | factor_2 | Dim1 | Dim2 | |
|---|---|---|---|---|
| gr_edad_1 | 0.579237 | -0.491174 | 0.111839 | 0.080417 |
| gr_edad_2 | 0.192983 | 1.017513 | 0.020054 | 0.557487 |
| gr_edad_3 | -0.530883 | -0.583340 | 0.187891 | 0.226857 |
| sexo_1 | 0.518828 | -0.530838 | 0.269182 | 0.281789 |
| sexo_2 | -0.518828 | 0.530838 | 0.269182 | 0.281789 |
| escolaridad_1 | 1.016567 | -0.727187 | 0.258352 | 0.132200 |
| escolaridad_2 | 0.165705 | 0.916920 | 0.022466 | 0.687880 |
| escolaridad_3 | -0.704873 | -1.002505 | 0.124211 | 0.251254 |
| escolaridad_4 | -0.912708 | -0.444503 | 0.147006 | 0.034868 |
| vivienda_1 | -0.501799 | -0.020746 | 0.755407 | 0.001291 |
| vivienda_2 | 1.505398 | 0.062237 | 0.755407 | 0.001291 |
La tabla anterior contiene las modalidades con sus respectivas etiquetas, las coordenadas de las modalidades sobre los dos primeros factores y los cuadrados de los cosenos de las modalidades sobre los dos primeros ejes factoriales.
Con relación al primer factor se nota que está definido por la posesión de vivienda. Situación que se corrobora con los cosenos cuadrados; recordemos que un valor de éstos cercano a \(1.0\) muestra una alta asociación entre la modalidad y el eje.
La correlación entre variables y dimensiones principales ayuda a identificar las variables que están más correlacionadas con cada dimensión. En este caso hacemos uso del \(cos2\) para graficarlas.
# Correlación variables con los ejes.
plot_var_corr(ca, df_ex1, X1)
La función mca_biplot() se usa para dibujar el biplot de individuos y las categorías de las variables:
# Plot primer plano factorial. (factor_1 and factor_2)
mca_biplot(ca, X1)
El plot anterior muestra un patrón global dentro de los datos. Las filas (individuos) están representadas por puntos y columnas (categorías de variables) por triángulos. La distancia entre cualquier punto de fila o columna da una medida de su similitud (o disimilitud). Los puntos de fila con un perfil similar se cierran en el mapa de factores. Lo mismo vale para puntos de columna.
El plot se puede interpretar de la siguiente manera:
Muestra la disposición de las modalidades y los individuos en el primer plano factorial.
Las modalidades de variables con un perfil similar se agrupan.
Las modalidades de variables correlacionadas negativamente se colocan en lados opuestos del origen de la gráfica.
La distancia entre los puntos de categoría y el origen mide la calidad de la variable categoría en el mapa de factores. Los puntos de categoría que están lejos del origen están bien representados en el mapa de factor.
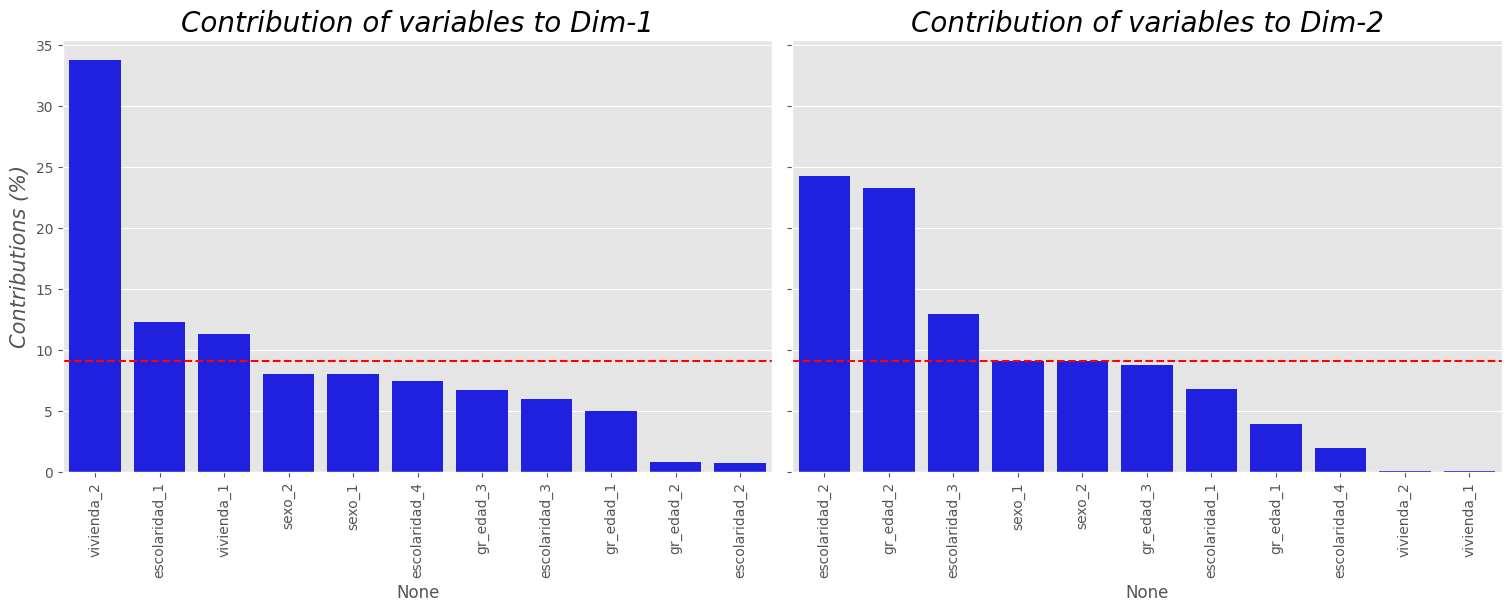
La contribución de las modalidades de las variables (en %) a la definición de las dimensiones se puede plotear de la siguiente manera.
plot_contrib_mca(ca, X1, choice="columns", axes1=1, axes2=2, top=11)
mca_triplot(ca, X1, width=1000, height=800, delta=1)
Comentarios:
Se destaca la diferenciación mostrada entre el grupo etáreo “anciano” (
gr_edad_3) y los demás; con una proximidad a la posesión de vivienda, lo que sugiere una relación directa entre la tenencia de vivienda y la edad. Similarmente se puede establecer para la edad y el nivel de escolaridad, los datos exhiben que el nivel de escolaridad superior (universitaria y otro) están asociadas con edades avanzadas.El segundo factor, se observa que es determinado por la escolaridad superior y secundaria.
Respecto al género se puede afirmar, a partir de estos datos, que no definen los ejes (se ubican en una bisectriz).
Para la variable edad la modalidad “joven” es indiferente en la definición de alguno de los dos ejes (se ubica en una bisectriz).
Las modalidades adulto y anciano son opuestas y están altamente ligadas con el segundo eje.
Comentarios generales:
Se observa que el primer eje factorial (factor 1) está altamente determinado por la variable posesión de casa propia.
El factor 1 determina dos tipologías de individuos, del lado izquierdo se puede afirmar que están quienes poseen un nivel de escolaridad universitario o más, con vivienda propia. En el lado derecho se encuentran quienes tienen un nivel de escolaridad a lo más de secundaria y que no tienen vivienda propia.
El segundo eje factorial (factor 2) está definido por las modalidades asociadas a la escolaridad, discriminada ésta por la modalidad secundaria frente a la modalidad universitario u otro.
Nota
Podemos usar el objeto MCA de la libreria Prince.
Pruebe este codigo:
mca = prince.MCA(
n_components=7,
n_iter=3,
copy=True,
check_input=True,
engine='sklearn',
random_state=42
)
mca = mca.fit(df_ex1)
display(mca.eigenvalues_summary)
# Tabla con información sobre los 2 primeros factores.
tmp = mca.column_coordinates(df_ex1)[[0,1]].rename(columns={0: "factor_1", 1: "factor_2"})
tmp1 = get_cos2(mca, df_ex1, choice = "columns")[["Dim1","Dim2"]]
display(tmp.merge(tmp1, left_index=True, right_index=True))
# Biplot librería prince
mca.plot(
df_ex1,
x_component=0,
y_component=1,
show_column_markers=True,
show_row_markers=True,
show_column_labels=False,
show_row_labels=False
).show()
Ejemplo 2.#
Para este ejemplo vamos a hacer uso del Dataset poison.csv. Estos datos son el resultado de una encuesta realizada a niños de primaria que sufrieron de malestares por presuntos alimentos en mal estado. Se les preguntó sobre sus síntomas y sobre lo que comían.
Los datos contienen 55 filas (individuos) y 15 columnas (variables).
poison = pd.read_csv(url_base + "poison.csv")
poison.head()
| Age | Time | Sick | Sex | Nausea | Vomiting | Abdominals | Fever | Diarrhae | Potato | Fish | Mayo | Courgette | Cheese | Icecream | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9 | 22 | Sick_y | F | Nausea_y | Vomit_n | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
| 1 | 5 | 0 | Sick_n | F | Nausea_n | Vomit_n | Abdo_n | Fever_n | Diarrhea_n | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_n | Icecream_y |
| 2 | 6 | 16 | Sick_y | F | Nausea_n | Vomit_y | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
| 3 | 9 | 0 | Sick_n | F | Nausea_n | Vomit_n | Abdo_n | Fever_n | Diarrhea_n | Potato_y | Fish_y | Mayo_n | Courg_y | Cheese_y | Icecream_y |
| 4 | 7 | 14 | Sick_y | M | Nausea_n | Vomit_y | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
Suponga que estamos interesados en establecer las relaciones entre las siguientes variables del Dataset:
Nausea Vomiting, Abdominals, Fever, Diarrhae, Potato, Fish, Mayo, Courgette, Cheese
df2 = poison.iloc[:, 4:]
df2.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 55 entries, 0 to 54
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Nausea 55 non-null object
1 Vomiting 55 non-null object
2 Abdominals 55 non-null object
3 Fever 55 non-null object
4 Diarrhae 55 non-null object
5 Potato 55 non-null object
6 Fish 55 non-null object
7 Mayo 55 non-null object
8 Courgette 55 non-null object
9 Cheese 55 non-null object
10 Icecream 55 non-null object
dtypes: object(11)
memory usage: 4.9+ KB
Vamos a cambiar los nombres de las modalidades por y y n en cada variable:
def replace_name_cate(string):
"""
Esta función cambia los nombre de las categorías en cada una de las variables categóricas a usar.
Example: "Sick_y", se reemplaza por "y". "Abdo_n" se reemplaza por "n".
"""
return re.findall("(?<=_)([\w]*)",string)[0]
df2 = df2.applymap(replace_name_cate)
df2 = df2.astype("category")
df2.head()
| Nausea | Vomiting | Abdominals | Fever | Diarrhae | Potato | Fish | Mayo | Courgette | Cheese | Icecream | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | y | n | y | y | y | y | y | y | y | y | y |
| 1 | n | n | n | n | n | y | y | y | y | n | y |
| 2 | n | y | y | y | y | y | y | y | y | y | y |
| 3 | n | n | n | n | n | y | y | n | y | y | y |
| 4 | n | y | y | y | y | y | y | y | y | y | y |
Recordemos que la cantidad de dimensiones máximas es:
Donde \(p\) es el número de las distintas modalidades en las variables categóricas y \(k\) es el número de variables
# Cantidad máxima de dimensiones.
pd.get_dummies(df2, drop_first=True).shape[1]
11
Los gráficos siguientes se pueden utilizar para identificar categorías de variables con una frecuencia muy baja. Estas tipos de variables pueden distorsionar el análisis y deben eliminarse.
# Resumen de la información.
# for col in df2.columns:
# plt.figure(figsize=(6,3))
# sns.countplot(df2[col])
# plt.show()
df2_mca2 = pd.get_dummies(df2) # Tabla disyunta (get_dummies data original).
mca2 = prince.CA(
n_components=11, n_iter=10, # Creamos y ajustamos un objeto CA de la
copy=True, check_input=True, # librería price sobre la tabla disyunta.
engine="sklearn", random_state=42
)
mca2 = mca2.fit(df2_mca2)
# Varianzas retenidas.
get_eigenvalue(mca2)
| eigenvalue | variance_percent | cumulative_variance_percent | |
|---|---|---|---|
| Dim1 | 0.335 | 33.523 | 33.523 |
| Dim2 | 0.129 | 12.914 | 46.437 |
| Dim3 | 0.107 | 10.735 | 57.172 |
| Dim4 | 0.096 | 9.588 | 66.760 |
| Dim5 | 0.079 | 7.883 | 74.643 |
| Dim6 | 0.071 | 7.109 | 81.752 |
| Dim7 | 0.060 | 6.017 | 87.769 |
| Dim8 | 0.056 | 5.577 | 93.346 |
| Dim9 | 0.041 | 4.121 | 97.467 |
| Dim10 | 0.013 | 1.304 | 98.771 |
| Dim11 | 0.012 | 1.229 | 100.000 |
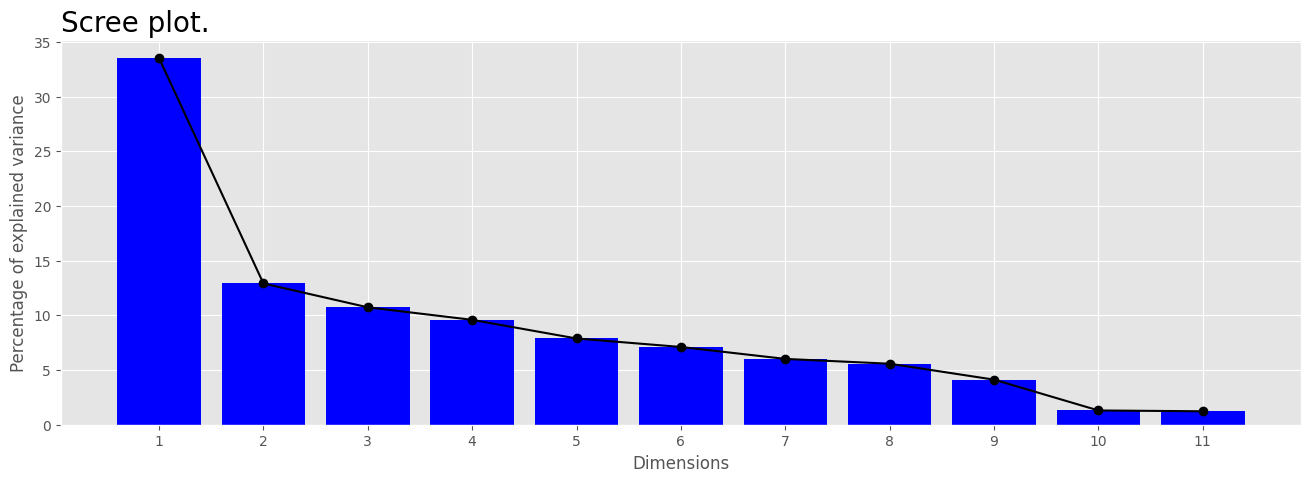
Para visualizar los porcentajes de inercia explicados por cada dimensión del CMA, usamos la función mca_screeplot():
mca_screeplot(mca2, figsize=(16,5))
La función mca_biplot() se usa para dibujar el biplot de individuos y categorías de las variables:
mca_biplot(mca2, df2_mca2, 1, 2)
La correlación entre variables y dimensiones principales ayuda a identificar las variables que están más correlacionadas con cada dimensión. En este caso hacemos uso del \(cos2\) para graficarlas.
plot_var_corr(mca2, df2, df2_mca2)
Se puede observar que, las variables: Diarrhae, Abdominals y Fever son las más correlacionadas
con dimensión 1. Así mismo, las variables Courgette y Potato son las más correlacionadas con la dimensión 2.
Las dimensiones 1 y 2 son suficientes para retener el \(46\%\) de la inercia total (variación) contenida en el datos. No todos los puntos se muestran igual de bien en las dos dimensiones.
mca_plot_cos2(mca2, df2_mca2, choice="columns", top=22, axes1=1, axes2=2)
Tenga en cuenta que las categorías variables Fish_n, Fish_y, Icecream_n y Icecream_y no están muy bien
representada por las dos primeras dimensiones. Esto implica que la posición de los puntos correspondientes
en el diagrama de dispersión debe interpretarse con cierta precaución.
La contribución de las modalidades de las variables (en %) a la definición de las dimensiones se puede plotear de la siguiente manera.
plot_contrib_mca(mca2, df2_mca2, choice="columns", top=22)
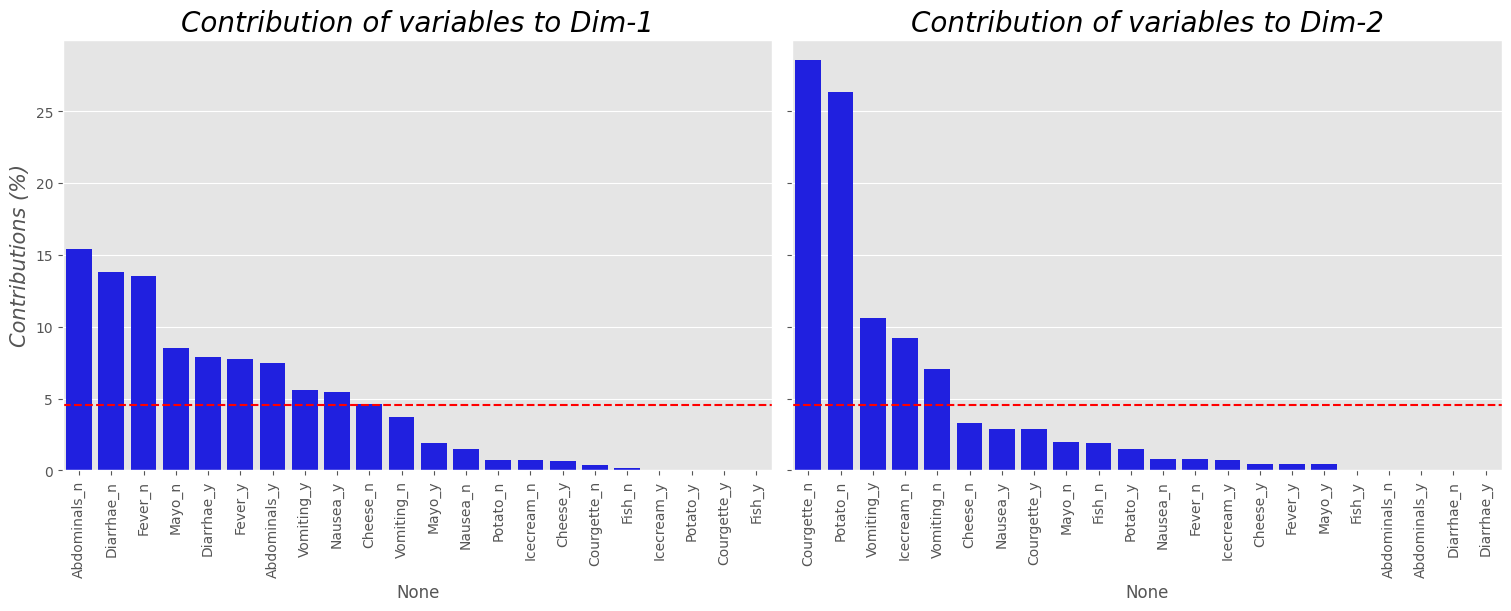
Del plot anterior se puede ver que:
Las categorías
Abdominals_n,Diarrhea_n,Fever_nyMayo_nson las más importantes en la definición de la primera dimensión.Las categorías
Courgette_n,Potato_n,Vomiting_yyIcecream_nson las que más aportan a la dimensión 2
Plots de los individuos y modalidades.#
mca_biplot(mca2, df2_mca2, dim1=1, dim2=2, size=10)
mca_biplot(mca2, df2_mca2, dim1=1, dim2=3, size=10)
mca_biplot(mca2, df2_mca2, dim1=2, dim2=3, size=10)
mca_triplot(mca2, df2_mca2, 800, 600, delta=1)
A apesar que no se tiene una alta inercia retenida por los 2 primeros ejes, se puede observar como se forman dos grupos de individuos que se relacionan via las modalidades de las diferentes variables categóricas. No olvide que los comentarios al respecto depende tanto de la contribución al eje y de los valores en \(cos2\).
Referencias:#
Análisis estadístico de datos multivariados. Díaz L & Morales M. Editorial: Publicaciones Facultad de ciencias. UNAL.
Multivariate Analysis II. Kassambara A. Disponible en: http://www.sthda.com/english/